深度学习笔记-深度学习基础(0)
什么是深度学习
人工智能、机器学习与深度学习
主要内容包括基本概念、机器学习与深度学习的特点、机器学习简史。
符号主义人工智能 一些专家认为,只要程序员精心编写足够多的明确规则来处理知识,就可以实现与人类水平相当的人工智能。富豪注意人工智能适合解决定义明确的逻辑问题,比如下国际象棋,但是难以给出明确的规则来解决更加复杂、模糊的问题,比如图像分类、语音识别和机器翻译。
专家系统 在经典的程序设计中(即符号主义人工智能的范式)中,人们输入的是规则(即程序),和需要根据这些规则进行处理的数据,系统输出的是答案。
机器学习 利用机器学习,人们输入的是数据和从数据中预期得到的答案,系统输出的是规则。这些规则随后可应用于新的数据,并使计算机自主生成答案。


机器学习系统是训练出来的,而不是明确地用程序编写出来的。机器学习尤其是深度学习,是以工程为导向的,想法更多地是靠实践来证明,而不是靠理论推导。
机器学习三要素:
-
输入数据点
-
预期输出的示例
-
衡量算法效果好坏的方法
机器学习和深度学习的核心问题在于有意义地变换数据,在于学习输入数据的有用表示(representation),使得数据更接近预期输出。
学习 机器学习中的学习指的是寻找更好数据表示的自动搜索过程。
机器学习技术定义 在预先定义好的可能性空间中,利用反馈信号的指引来寻找输入数据的有用表示。
深度学习 深度学习是机器学习的一个分支领域,强调从连续的层(layer)中进行学习,深度指的是一系列连续的表示层。可以将深度网络看作多级信息蒸馏操作:信息穿过连续的过滤器,其纯度越来越高(即对任务的帮助越来越大)。
深度学习技术定义 学习数据表示的多级方法。
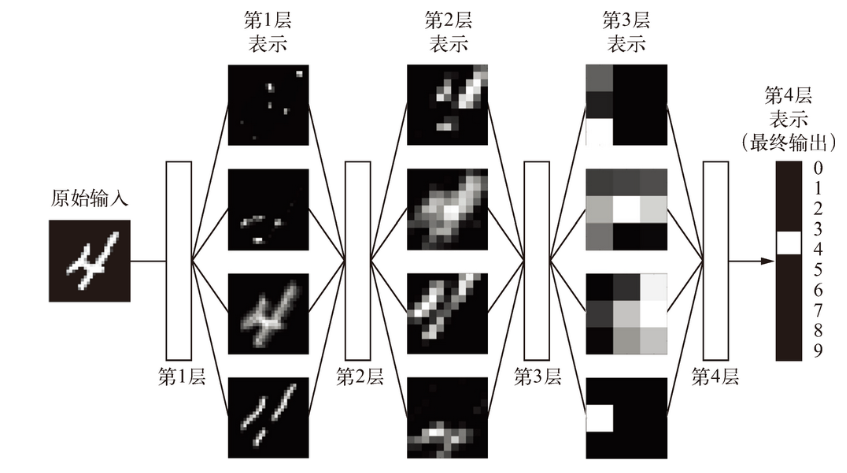
深度学习工作原理

神经网络学习的意思是为神经网络的所有层找到一组权重值,使得该网络能够将每个示例输入与其目标值正确地一一对应。
损失函数(loss function) 衡量输出与期望值之间的距离,也叫目标函数(objective function)。
优化器(optimizer) 可以利用距离值作为反馈信号来对权重进行微调,以降低当前示例对应的损失值,这就是所谓的反向传播(back propagation)。
机器学习简史
概率建模
概率建模是统计学原理在数据分析中的应用,其中最有名的就是朴素贝叶斯算法和logistic回归。
早期神经网络
贝尔实验室于1989年第一次成功实现了神经网络的实践应用,将卷积神经网络的早期思想与反向传播算法相结合,应用于手写数字分类问题,即LeNet网络。
核方法
利用核函数(kernel funciton)计算映射到高维空间的数据中点对之间的距离,并在新的空间中找到良好的决策超平面。和函数通常是人为选择的,而不是从数据中学到的,对于SVM来说,只有分割超平面是通过学习得到的。
SVM通过两步来寻找决策平面:
- 将数据映射到一个高维表示,这时决策边界可以用一个超平面表示
- 尽量让超平面与每个类别最近的数据点间隔最大化,计算良好的决策边界
SVM在简单分类问题上表现出很好的性能,并且适用于严肃的数学分析;但是SVM很难扩展到大型数据集,并且在图像分类等感知问题上的效果也不好。
决策树、随机森林、梯度提升机
随机森林 将躲棵决策树的输出集成在一起。
梯度提升机 通过合并多个决策树来构建一个更为强大的模型,采用连续的方式构造树,每棵树都试图纠正前一棵树的错误。(XGBoost)
深度学习
特点
- 深度学习将特征工程完全自动化。
- 通过渐进的、逐层的方式形成越来越复杂的表示。
- 对中间的渐进表示共同进行学习。
- 扩展性强,可以并行计算。
- 多功能可复用,可以迁移学习,可以连续在线学习,模型可以用于其它用途。
算法改进
- 更好的激活函数
- 更好的权重初始化方案
- 更好的优化方案
- 有利于梯度传播的方法,批标准化、残差连接、深度可分离卷积