自然语言处理(1)-实战微博情感分析
实战微博情感分析
介绍
使用word2vec、jieba分词、BiLSTM模型对微博内容进行情感分类。
整体思路
涉及的主要内容有:
-
微博情感分析数据集的获取。
-
对jieba分词进行简要介绍,并使用它完成对微博句子的分词任务。
-
对word2vec词向量模型进行简单介绍,并使用预训练的中文词向量对原始数据进行转换。
-
简单介绍,构建并使用BiLSTM模型进行训练,完成情感分析任务。
-
算法的不足之处和需要改进的地方。
微博情感分析数据集
常用的数据集有:
-
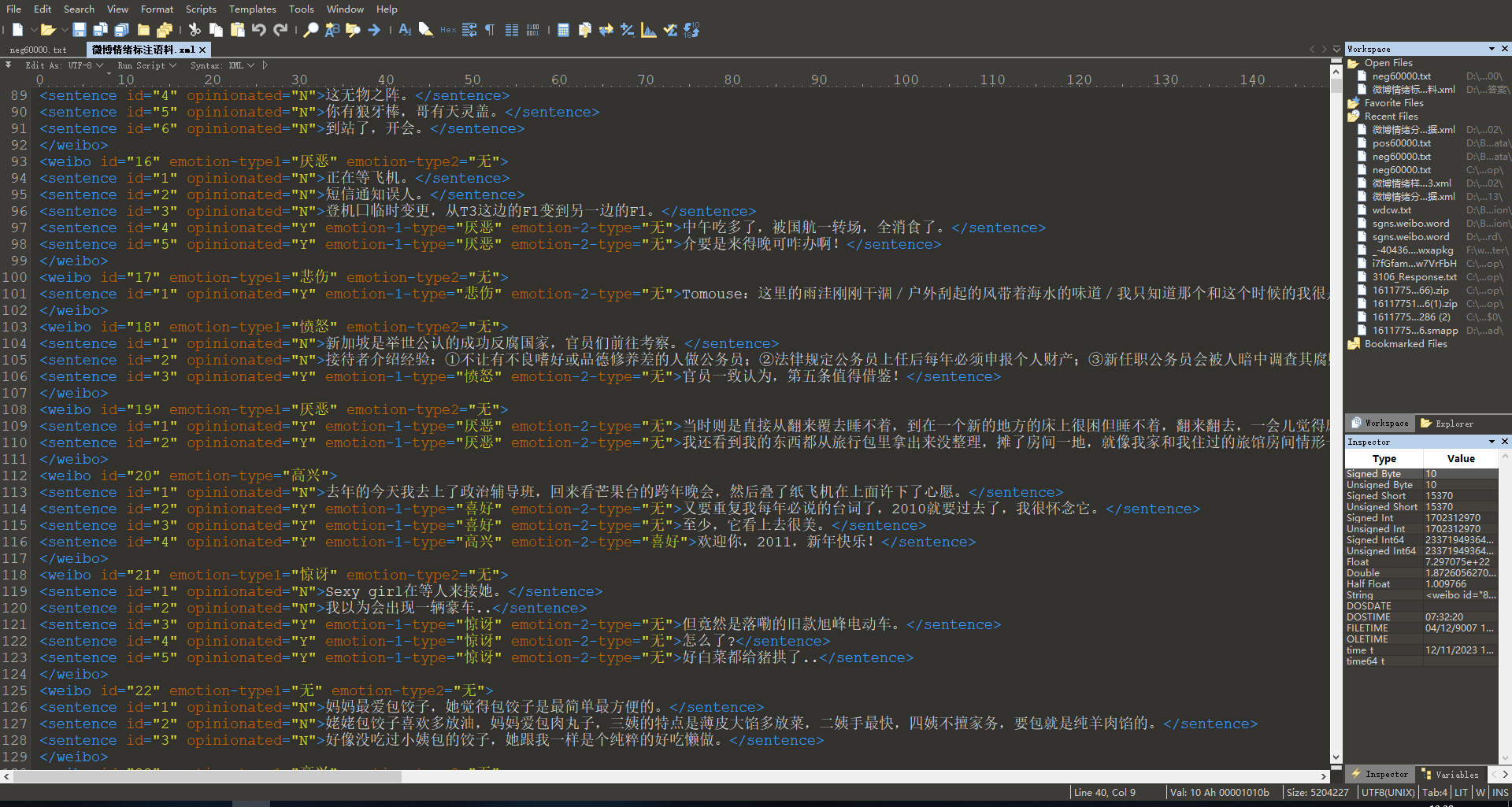
NLP&CC 2013: 该数据集是xml格式,有大概3w条数据,17w条数据作为测试样本(手动滑🐔),分为none、like、disgust、anger、happiness、fear、sadness、surprise等几个类别,其中none又占绝大多数。
如下图所示:
-
COAE2013:没有进行下载,也就不具体说明了,同样据说数据较少。
-
(
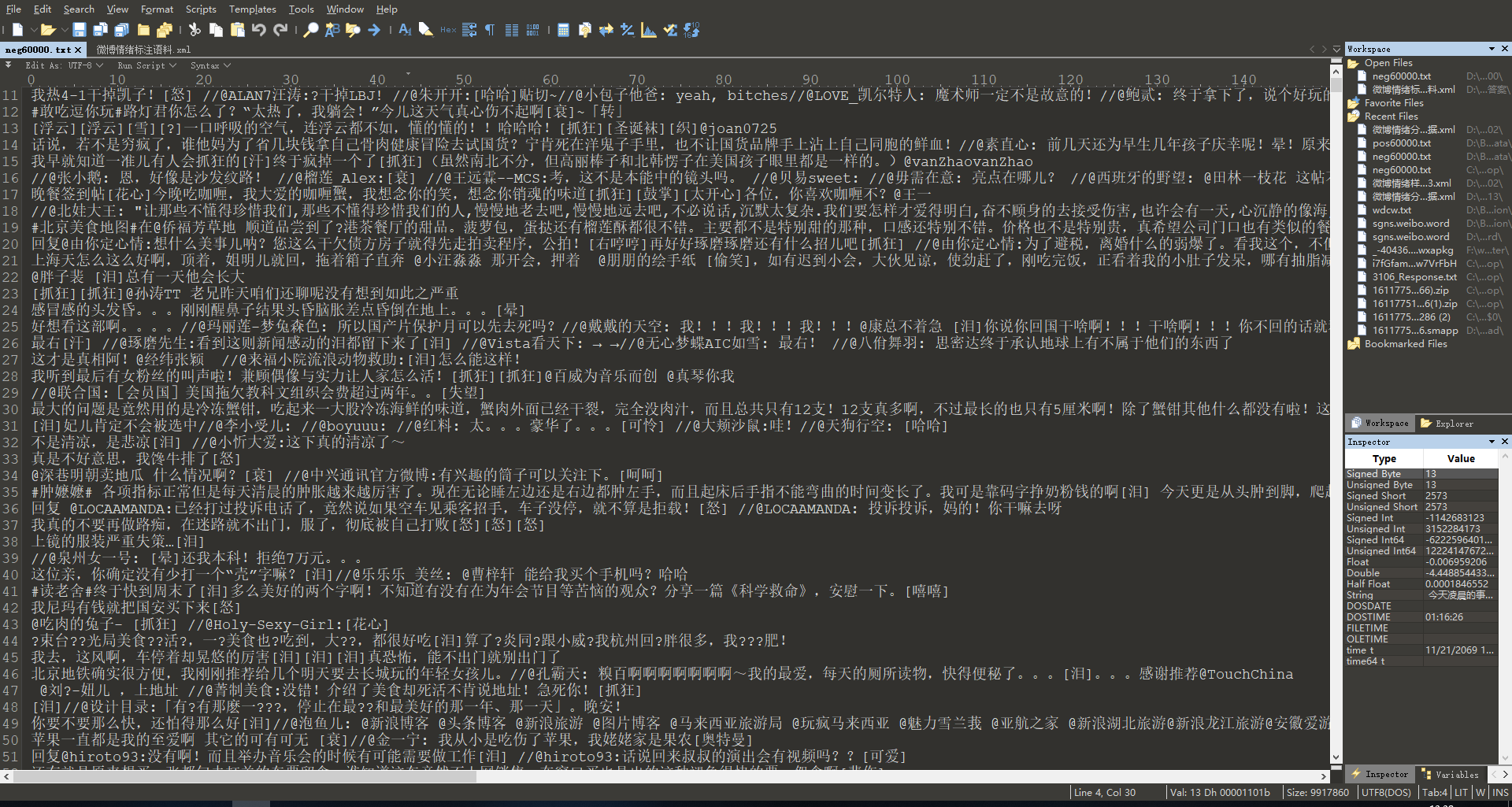
不知道名字的数据集):我使用的是一个CSDN上的数据集,txt格式,数据已经清理好,分为6w条积极情绪和6w条消极情绪,下载地址在文末。如下图所示:
jieba介绍
结巴中文分词涉及到的算法包括: (1) 基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG); (2) 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合; (3) 对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。
jieba的主要功能有:
-
分词
-
添加自定义词典
-
关键字提取
-
词性标注
我们主要使用它的分词功能,HMM模型原理和viterbi算法原理在文末的有传送门。
jieba支持三种分词模式:
- 精确模式,适合文本分析。
- 全模式,把所有可以成词的词语都扫描出来,不能解决歧义。
- 搜索引擎模式,在精确模式的基础上对长词再次切分,适合搜索引擎分词。
分词功能调用方法
-
jieba.cut接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型 -
jieba.cut_for_search接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细 -
jieba.cut以及jieba.cut_for_search返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode),或者用 -
jieba.lcut以及jieba.lcut_for_search直接返回 list -
jieba.Tokenizer(dictionary=DEFAULT_DICT)新建自定义分词器,可用于同时使用不同词典。jieba.dt为默认分词器,所有全局分词相关函数都是该分词器的映射。
代码示例:
# encoding=utf-8
import jieba
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式
seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式
print(", ".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list))
输出:
【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学
【精确模式】: 我/ 来到/ 北京/ 清华大学
【新词识别】:他, 来到, 了, 网易, 杭研, 大厦 (此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了)
【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
word2vec介绍
我们使用Chinese Word Vectors 中文词向量,可以直接下载对应语料库下预训练好的模型。
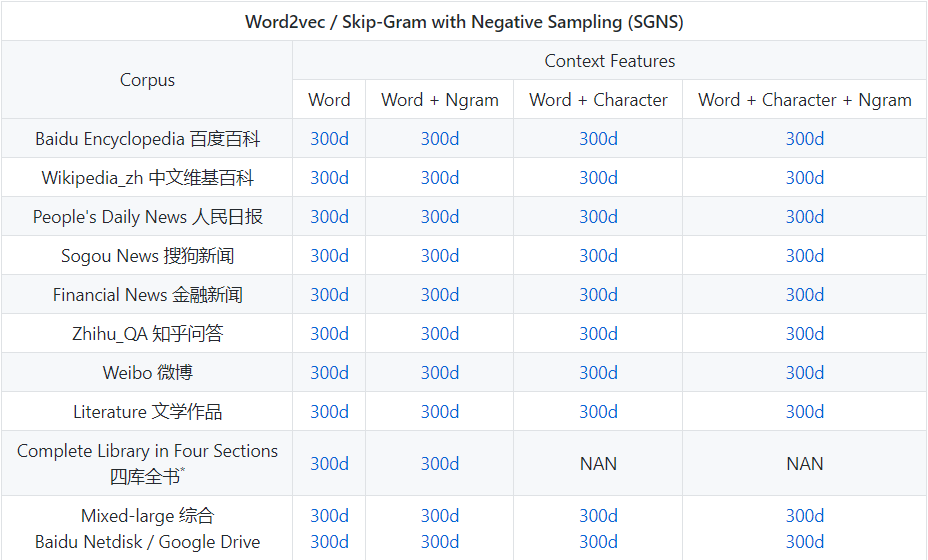
这里我下载的是稠密矩阵的微博Word文件。
该模型词向量为300维,浮点数精确到小数点后五位,有19W+个词向量,同时里面包含了中文标点。
如下图所示:
下载之后,可以按照 GitHub ana_eval_dense.py 里的代码加载词向量文件,并转换为矩阵形式
部分代码如下:
def read_vectors(path, topn): # read top n word vectors, i.e. top is 10000
lines_num, dim = 0, 0
vectors = {}
iw = []
wi = {}
with open(path, encoding='utf-8', errors='ignore') as f:
first_line = True
for line in f:
if first_line:
first_line = False
dim = int(line.rstrip().split()[1])
continue
lines_num += 1
tokens = line.rstrip().split(' ')
vectors[tokens[0]] = np.asarray([float(x) for x in tokens[1:]])
iw.append(tokens[0])
if topn != 0 and lines_num >= topn:
break
for i, w in enumerate(iw):
wi[w] = i
return vectors, iw, wi, dim
vectors, iw, wi, dim = read_vectors(vectors_path, topn) # Read top n word vectors. Read all vectors when topn is 0
# Turn vectors into numpy format and normalize them
matrix = np.zeros(shape=(len(iw), dim), dtype=np.float32)
for i, word in enumerate(iw):
matrix[i, :] = vectors[word]
matrix = normalize(matrix)
注意:windows下需要将with open(path) as f 改成 with open(path,encoding=”utf-8”) as f
也可以使用谷歌的word2vec的python库:https://pypi.org/project/word2vec/
直接使用
word2vec.load("文件位置.txt")
即可完成导入
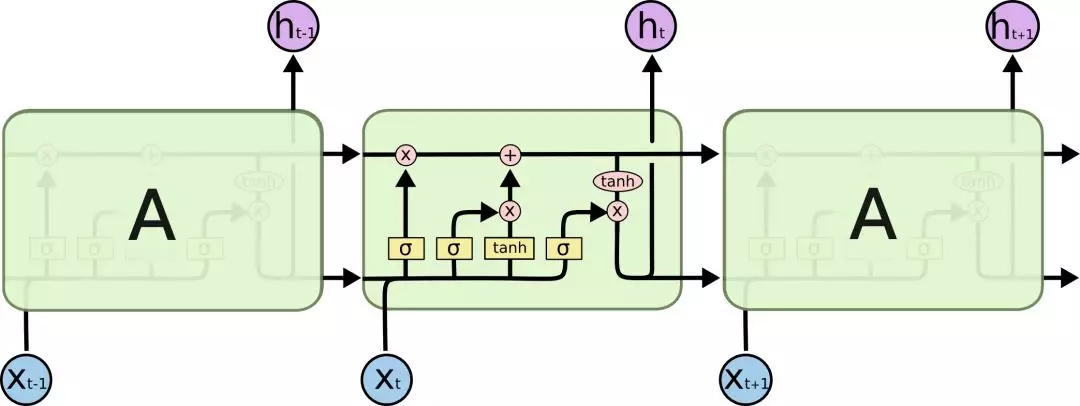
BiLSTM介绍
简单来讲,LSTM是在RNN的基础上加入了遗忘门和记忆门;
BiLSTM是在LSTM的基础上,变为了双向循环。
下图为LSTM:
下图为Bi-LSTM:
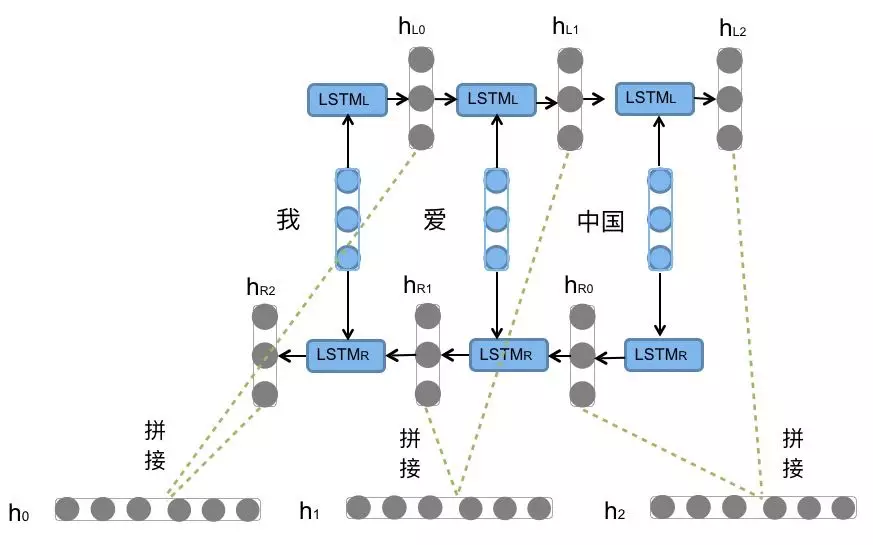
使用Bi-LSTM用于情感分类问题可以充分考虑在上下文中,词语的具体感情色彩,更好的捕捉双向的语义依赖。
Keras中已经集成了Bi-LSTM模型,建立模型的代码如下:
# 建立线性模型
model = Sequential()
# 添加Bi-LSTM层
model.add(Bidirectional(LSTM(64,dropout=0.2,return_sequences=True),input_shape=(128,300)))
# 将输出平坦化
model.add(Flatten())
# 添加一个全连接层(神经元)
model.add(Dense(1))
# 使用sigmod函数进行二分类
model.add(Activation("sigmoid"))
# 损失函数使用二元交叉熵,优化器使用adam,衡量标准使用准确率
model.compile(loss="binary_crossentropy", optimizer="adam",metrics=["accuracy"])
完整代码(粗糙版):
可在github中克隆:https://github.com/msxfXF/NLPWeibo
train.py
import numpy as np
import random
import word2vec
import jieba
from keras import Sequential
from keras.layers import LSTM,Bidirectional,Activation,Dense,Flatten
from keras_preprocessing import sequence
w2v = word2vec.load("sgns.weibo.word.txt")
strs = []
strs_label = []
with open("data/train_0.txt","r",encoding="utf-8") as f:
lines = f.readlines()
for line in lines:
strs.append(line)
strs_label.append(0)
with open("data/train_1.txt",encoding="utf-8") as f:
lines = f.readlines()
for line in lines:
strs.append(line)
strs_label.append(1)
shuffle_index = np.random.permutation(np.arange(len(strs)))
strs = np.array(strs)[shuffle_index]
y = np.array(strs_label)[shuffle_index]
x = np.zeros(shape=(len(strs),128,300), dtype=np.float32)
for i,str in enumerate(strs):
res_cuts = jieba.cut(str[:128])
for j,res_cut in enumerate(res_cuts):
if res_cut in w2v:
x[i,j,:] = w2v[res_cut]
model = Sequential()
model.add(Bidirectional(LSTM(64,dropout=0.2,return_sequences=True),input_shape=(128,300)))
model.add(Flatten())
model.add(Dense(1))
model.add(Activation("sigmoid"))
model.compile(loss="binary_crossentropy", optimizer="adam",metrics=["accuracy"])
print(model.summary())
model.fit(x,y,validation_split=0.1,batch_size=32, epochs=3)
model.save('weibo.h5')
demo.py
import numpy as np
import random
import word2vec
import jieba
import sys
from keras import Sequential,models
from keras.layers import LSTM,Bidirectional,Activation,Dense,Flatten
from keras_preprocessing import sequence
if __name__ == "__main__":
if(len(sys.argv)>=2):
w2v = word2vec.load(r"sgns.weibo.word.txt")
x = np.zeros(shape=(1,128,300), dtype=np.float32)
model = models.load_model('weibo.h5')
print(model.summary())
for i,str in enumerate(sys.argv[1:]):
res_cuts = jieba.cut(str)
for j,res_cut in enumerate(res_cuts):
if res_cut in w2v:
x[0,j,:] = w2v[res_cut]
print(res_cut)
res = model.predict(x)
print(str)
print(res)
else:
pass
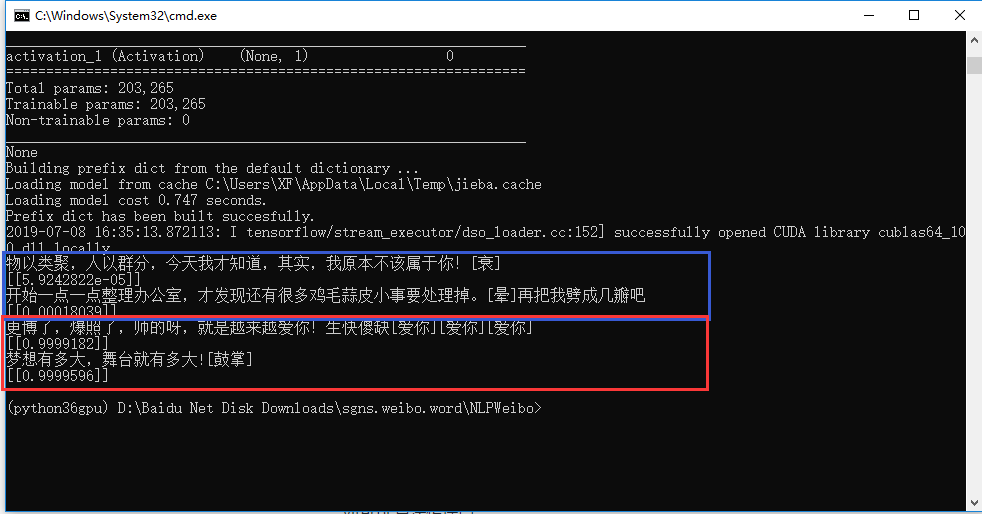
对数据进行划分后,训练集:测试集:验证集 = 107820:11980:200,训练得到的结果在测试集上的精确度在96.8%左右。(因为去学车了,只训练了3个epoch,其实已经过拟合了)
测试效果:
存在的问题
当然还非常非常不完善!!!
个人感觉是数据量太少,一些数据的相关性有些高,比如很多微博里都有 “哭了” 这个词。
另外,模型一些参数也没有进行调优,代码比较粗糙,直接读入所有数据占用内存较大。
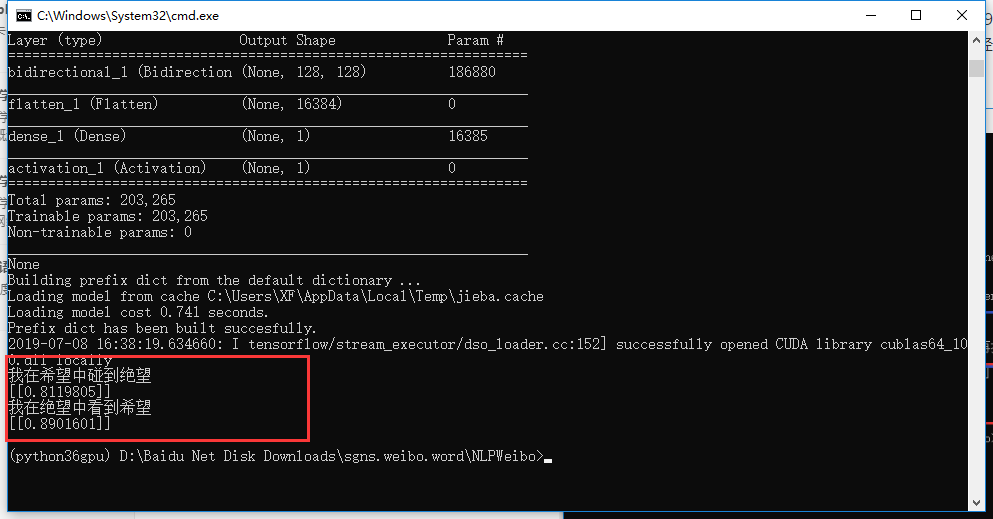
事实证明,想通过12W句话,0基础学会中文所有情感,对机器来讲还是有点难度的!
参考资料和相关网址
微博数据集:
https://download.csdn.net/download/weixin_38442818/10214750
jieba分词GitHub:
https://github.com/fxsjy/jieba
结巴分词HMM模型原理:
https://zhuanlan.zhihu.com/p/40502333
HMM隐马尔科夫模型传送门:
https://blog.csdn.net/zxm1306192988/article/details/78595933 viterbi 算法传送门:
https://www.zhihu.com/question/20136144/answer/37291465
详细Bi-LSTM介绍:
https://www.jiqizhixin.com/articles/2018-10-24-13