深度强化学习简介
深度强化学习笔记(0)-深度强化学习简介
原文链接
Deep Reinforcement Learning Course —— An introduction to Reinforcement Learning:
https://www.freecodecamp.org/news/an-introduction-to-reinforcement-learning-4339519de419/
介绍
强化学习是机器学习的的一部分,智能体(agent)通过训练可以学习如何在不同状态(status)下进行相应的动作(actions)。
在本系列文章中,我们将看到不同的强化学习模型,包括:Q-learning、深度Q-learning、策略梯度、Actor Critic和PPO等。
本文将介绍:
- 什么是深度强化学习、什么是奖励(rewards)?
- 强化学习的三种方法
- 深度强化学习的深度是指什么?
在学习之前,我们需要理解深度强化学习的基本概念:
寻找一个合适的函数,将观察到的环境(environment)作为输入,目标是最大化回报(收益 reward)(从经验中学习)
The idea behind Reinforcement Learning is that an agent will learn from the environment by interacting with it and receiving rewards for performing actions.
强化学习过程

超级马里奥(agent) 过关的过程,可以看作一个循环:
- 智能体从环境中获取第一个状态S0(从超级马里奥游戏状态中获取到第一帧)
- 根据状态S0,智能体做出动作A0(马里奥向右移动)
- 环境变为一个新的状态S1(游戏中的新一帧)
- 环境给予一定的收益(马里奥没死 reward +1)
RL循环,输出一个由状态、动作、收益组成的序列,智能体的目标就是最大化预期累积收益。
收益假设的核心思想
强化学习是基于奖励假设,所有的优化目标,都可以用预期累计收益来进行表示。为了找到最优化的行为,我们需要将预期累计收益最大化。
每个时间的累积收益可以表示为:

即:
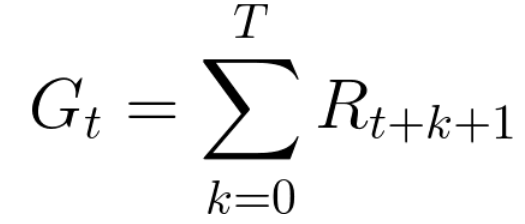
但是,我们需要考虑到在游戏开始时,提供的奖励更有可能发生,因为它们比长期的未来收益更有可能被预测。

假设智能体是老鼠,它的目标是在被猫吃掉之前获得更多的奶酪。
正如我们在图中看到的,老鼠在它附近吃奶酪的可能性比在猫附近吃奶酪的可能性更高。
因为老鼠越接近猫,就会越危险。
因此,即使猫附近的奶酪更多,但是它的预期累计收益将大打折扣,因为老鼠不确定是否能活着吃到它。
为了减小收益,我们这样做:
定义一个变量gamma表示折扣率,取值在0-1之间。
- gamma越大,折扣越小,表示智能体更在意长期的收益
- 反之,gamma越小,折扣越大,智能体更在意短期收益(即离老鼠最近的奶酪)
增加折扣后的预期累计收益公式为:
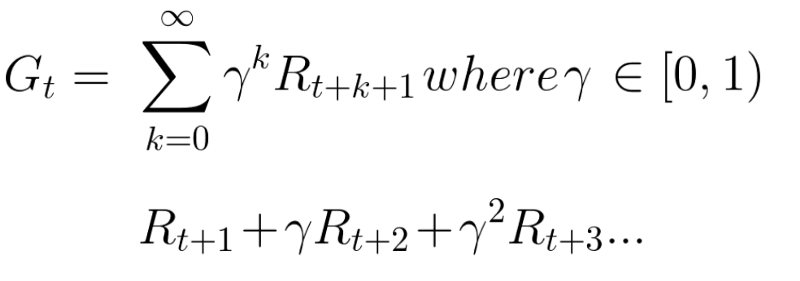
随着时间的增长,收益以指数衰减,表示未来的收益越来越不可能发生。
Episodic or Continuing tasks
episodes:智能体与环境交互的子片段(任意重复的交互)。
Episodic task:片段式任务,有起点,有终点。例如马里奥:

Continuing Tasks:连续式任务,永远持续,无终点。例如股票自动交易:
Monte Carlo vs TD Learning methods
两种学习的方法:
Monte Carlo:在每个episode结束时计算预期累积收益
TD Learning(Temporal Difference Learning) :在每个时间片段中学习

在TD Learning中,R为每一步的收益、α为学习率、γ为折扣率1
TD目标只是估计值
探索与利用
- 探索:寻找更多环境信息
- 利用:利用已知信息来最大化收益
RL智能体的目标是最大化预期收益,所以可能陷入一个困境。
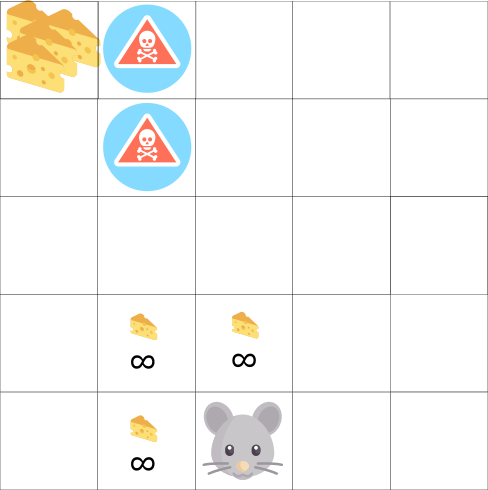
例如,在老鼠附近有无穷多小的奶酪(+1),但在顶端有巨大的奶酪(+1000)。当我们仅仅关注收益时,老鼠永远不会到达最顶端的大奶酪,只会在附近利用信息获取小的奶酪。
强化学习的三种方法
强化学习的三种方法分别是:基于收益、基于策略、基于模型。
基于收益
在基于收益的RL中,目标是优化收益函数V(s),即使得预期收益最大化。每个状态的value是从开始状态到结束状态所预期的收益总和。
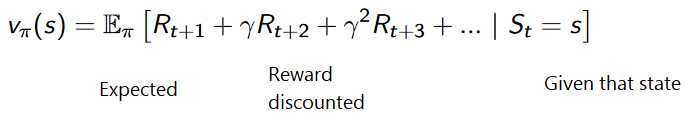
智能体会使用收益函数,在每一步(状态)中进行选择,并选取收益最高的状态。

智能体依次选择的收益为 -7,-6,-5,-4。。。
基于策略
在基于策略的RL中,我们抛弃了收益函数,直接优化策略函数 π(s),策略函数是定义给定时间下,智能体的行为的函数。
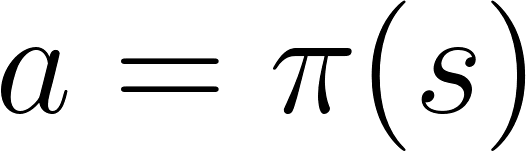
通过训练策略函数,可以将每个状态映射到最佳的动作上,两种类型的策略:
- 确定策略
- 随机策略

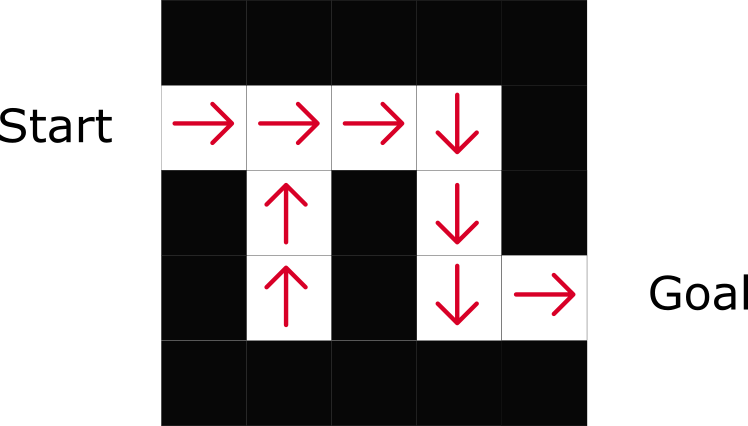
通过基于策略的方式,直接给出了每一步的最佳动作。
基于模型
通过建立环境模型,学习环境的动态情况,对环境的反馈做出反应。
例如在CartPole中,通过建立环境模型,在考虑了之前和当时位置后,预测下一个位置。
环境模型在物理世界的行动策略里有非常重要的作用,但是需要在每个环境中用不同的模型表示。
深度强化学习简介
深度强化学习(Deep Reinforcement Learning,DRL)引入深度神经网络来解决强化学习问题,故称为“deep”
在之前的强化学习中,我们使用Q表来找到每个状态下相应动作的收益
在DRL中,我们使用神经网络(基于状态)来对Q值进行近似。
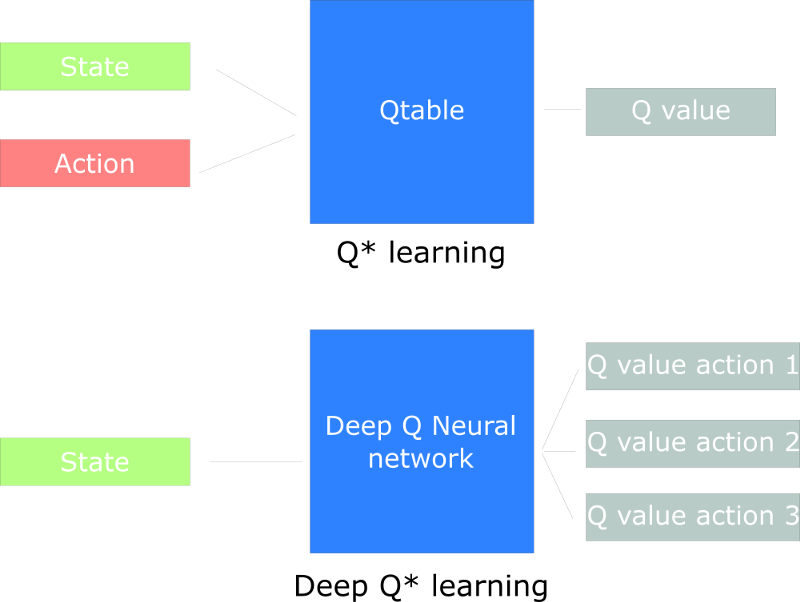
在之后的blog中会有更多介绍。