AEPO 论文精读:Web Agent RL 里的熵不是越高越好
解读 AEPO 如何在 rollout 和 policy update 两阶段平衡高熵探索,缓解 Web Agent 强化学习中的分支坍缩和梯度裁剪问题。
Paper Reading · arXiv:2510.14545
一句话:AEPO 把 Web Agent RL 里的“熵”从单纯鼓励探索的信号,改造成需要被预算、惩罚和梯度共同平衡的训练变量。
论文:Agentic Entropy-Balanced Policy Optimization
作者:Guanting Dong, Licheng Bao, Zhongyuan Wang, Kangzhi Zhao, Xiaoxi Li, Jiajie Jin, Jinghan Yang, Hangyu Mao, Fuzheng Zhang, Kun Gai, Guorui Zhou, Yutao Zhu, Ji-Rong Wen, Zhicheng Dou
机构:Renmin University of China, Kuaishou Technology · 会议:WWW 2026(论文页标注)
链接:arXiv · PDF · Code
适合读者:熟悉 GRPO / PPO、tool-use agent、Web search agent 或 RLVR 的读者。阅读时长约 20 分钟。
高熵探索会带来两种训练病
论文把 agentic RL 中的熵问题拆成两类:rollout 阶段的高熵分支坍缩,以及 policy update 阶段高熵 token 梯度被 clipping 吃掉。(p.2-p.3, S003-S004)
先分预算,再惩罚连续分支
AEPO 先用问题熵和工具调用熵决定全局采样与局部分支采样的预算,再降低连续高熵工具步继续分支的概率。(p.4-p.5, S007-S008)
高熵 token 不该一刀切裁掉梯度
方法在 clipping 项里加入 stop-gradient,保留并重缩放有正 advantage 的高熵 token 梯度,同时用熵感知 advantage 强化不确定但正确的探索 token。(p.5-p.6, S009)
14 个 benchmark 上优于 7 类 RL baseline
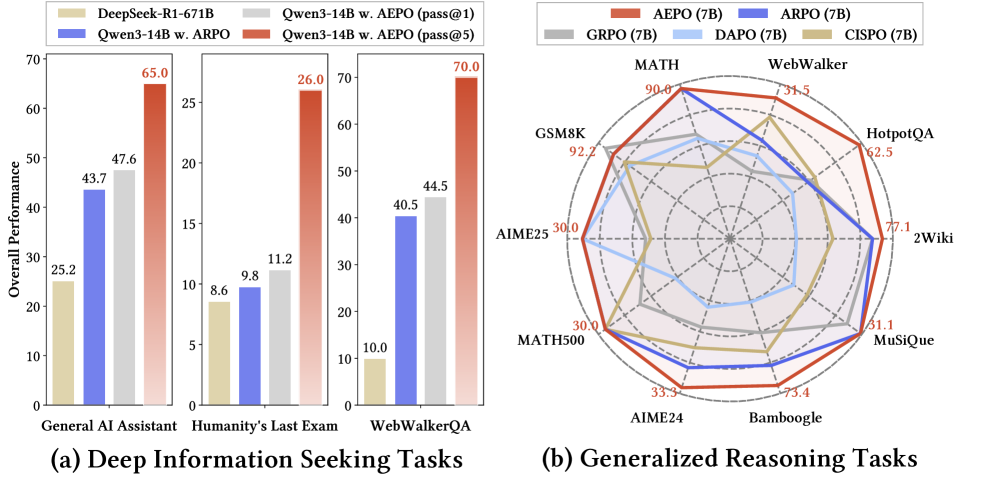
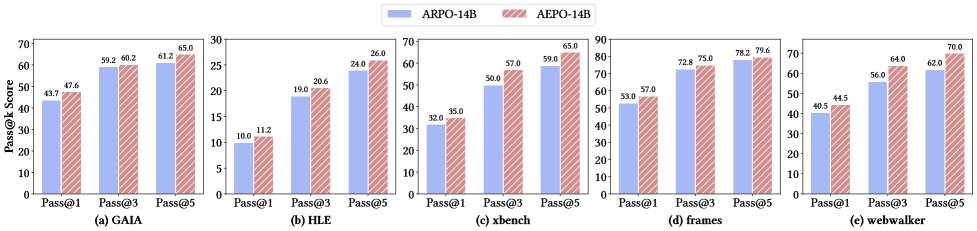
Qwen3-14B + AEPO 在 GAIA / HLE / WebWalkerQA 上 Pass@1 分别为 47.6 / 11.2 / 43.0,Pass@5 分别为 65.0 / 26.0 / 70.0。(p.1, S001; p.7-p.9, T001-S011)
我的快速判断
- 核心贡献不是“让熵更高”:它真正想解决的是 agentic RL 里熵信号过强导致的资源错配和梯度学习失败。
- 最值得借鉴的工程思想:把 rollout budget 从固定经验参数改成由问题熵 / 工具熵动态决定;这对昂贵 Web 搜索和浏览工具尤其重要。
- 最需要谨慎的地方:论文实验规模是 1K 训练样本、Bing 搜索、16 张 H800;复现时搜索 API、judge、网页截断和工具失败率都会影响结论。(p.6, S010)
1. 这篇论文到底解决什么问题?
Web Agent 与普通单轮推理模型的差异在于:它不是只生成一段答案,而是在搜索、打开网页、总结、执行代码等工具环境中进行多轮交互。SFT 能模仿已有轨迹,但很难发现新的、可泛化的工具使用策略;RLVR / GRPO 这类强化学习可以用结果奖励训练 agent,但经典 trajectory-level RL 往往没有充分处理“多轮工具交互”里的探索结构。(p.1-p.2, S002)
近来的 agentic RL 方法常用熵来定位不确定的工具调用步骤:高熵意味着模型不确定,似乎应该多采样、多分支、多探索。AEPO 的出发点是:高熵确实有价值,但如果只把高熵当成“继续分支”的理由,会在 rollout 和参数更新两端同时出问题。(p.2-p.3, S003-S004)
2. 背景:高熵探索为什么会变成问题?
论文先做了 pilot experiments,试图量化 agentic RL 中“熵驱动探索”的副作用。这里的 token entropy 来自模型在第 t 步生成 token 时的概率分布:分布越平,熵越高,说明模型越不确定;工具调用相关 token 和逻辑转折 token 往往会呈现较高熵。(p.3, S004)
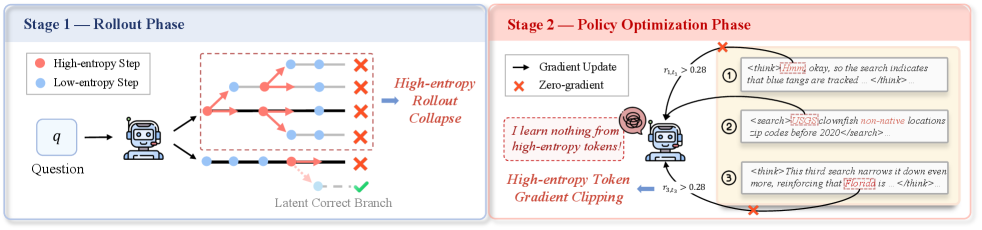
2.1 问题一:High-Entropy Rollout Collapse
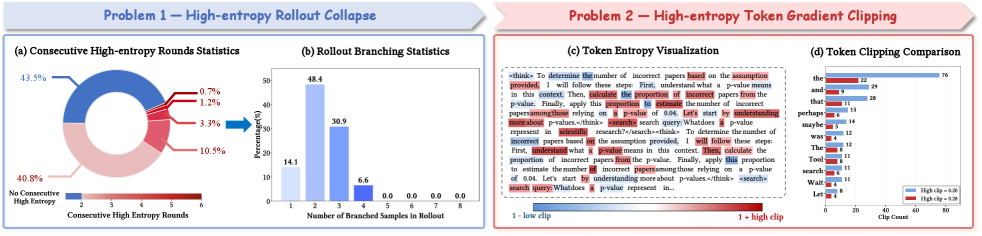
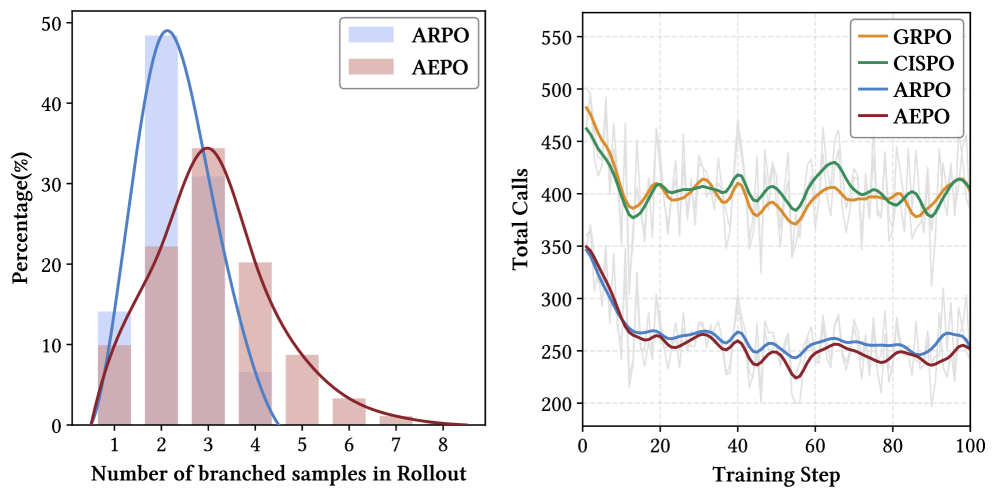
如果某条轨迹连续出现高熵工具调用,树状 rollout 会倾向于在这条路径上反复分支。论文统计发现,高熵工具调用轮次具有“连续性”:连续高熵工具轮占 56.5%,孤立高熵轮占 43.5%,最长可连续 6 轮;在分支预算为 8 的 rollout batch 中,93.4% 的分支集中在 1-3 条轨迹上。(p.3, S003)
直觉上,这类似搜索系统里的“局部最吸引人的岔路”。高熵告诉你这里有不确定性,但并不保证这条路是最值得继续烧预算的路;如果只盯着它,rollout 的覆盖面反而变窄。
2.2 问题二:High-Entropy Token Gradient Clipping
第二个问题发生在 policy update。高熵 token 往往对应逻辑连接、反思、工具调用等功能性行为,它们正是 agent 学会探索路径和工具模式的关键 token。但 vanilla RL 的 clipping 会把超出范围的梯度统一裁掉;论文认为这会在训练早期就让高熵探索 token 缺少梯度支持,导致模型固化在少数范式化推理路径里。(p.3, S004)
3. 方法总览:AEPO 在 rollout 和 update 两阶段平衡熵
AEPO 的结构非常清楚:第一部分是 Dynamic Entropy-Balanced Rollout,解决 rollout 预算如何分配、怎样避免连续高熵分支过度集中;第二部分是 Entropy-Balanced Policy Optimization,解决高熵 token 在梯度更新中如何被保留和加权。(p.4, S006)
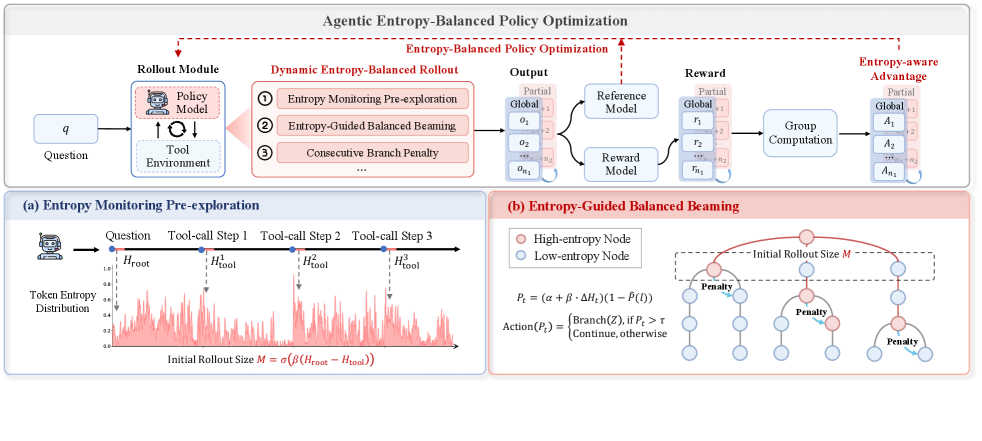
3.1 Dynamic Entropy-Balanced Rollout:先决定预算该花在哪里
论文把总 rollout budget 记为 k,其中 m 用于全局轨迹采样,k - m 用于高熵工具步骤上的局部分支采样。AEPO 不再固定 m,而是先生成一条完整工具轨迹,估计问题本身的初始熵 H_root 和工具调用引入的平均熵 H_tool_avg。(p.4, S007)
核心规则是:如果 H_root - H_tool_avg > 0,说明初始问题本身不确定性更大,应增加全局探索;如果 H_root - H_tool_avg < 0,说明工具交互带来的不确定性更大,应把更多预算给局部分支。论文用 sigmoid 和敏感度参数 β 把这个差值映射到 m。(p.4, S007)
直观版 AEPO rollout:
1. 对 query q 先跑一条完整工具轨迹。
2. 估计 H_root 与 H_tool_avg。
3. m = k * sigmoid(beta * (H_root - H_tool_avg))
4. 用 m 条全局轨迹覆盖不同解题方向。
5. 用 k - m 个分支预算处理高熵工具调用步骤。
6. 如果同一条链连续高熵分支,逐步降低继续分支概率。3.2 连续分支惩罚:高熵不是无限续杯券
在 adaptive rollout 中,AEPO 会持续监控工具调用后的 entropy variation,并记录每条链在当前步骤之前已经连续出现多少次高熵分支。随着连续分支计数 l 增大,继续分支的概率会被线性惩罚;论文实现中使用 P(l)=0.2·l 作为连续分支惩罚概率。(p.5-p.6, S008-S010)
这一步的工程含义很明确:模型仍然可以在高熵工具节点上分支,但不能因为某条路径一直高熵就把所有预算吸走。换句话说,AEPO 不是压制探索,而是把探索从“局部贪婪”改成“预算约束下的覆盖”。
3.3 Entropy-Balanced Policy Optimization:保留有价值的高熵梯度
在 policy update 端,AEPO 认为传统 clipping 过于粗暴:高熵 token 可能是噪声,也可能是正确探索的关键行为。它借鉴 clipping-optimized RL 的思路,在高熵 clipping 项中加入 stop-gradient,从而让 forward 计算保持不变,但在 backward 时对满足条件的高熵 token 梯度做保留和重缩放。(p.5, S009)
论文给出的条件可以粗略理解为:当 importance ratio δ > 1 + ε_h 且 token 的 advantage 为正时,AEPO 不直接把梯度裁掉,而是把它重缩放到 1 + ε_h;其他情况仍按 GRPO 式 clipping 处理。这样做的目标是让模型从“高熵但有效”的探索 token 中学习,而不是让 clipping 把它们统一归零。(p.5, S009)
此外,AEPO 还加入 entropy-aware advantage estimation:传统 outcome-based RL 会把同一条序列内所有 token 分到相同 answer-level advantage,而 AEPO 用 token entropy 进一步 reshape advantage,让不确定但最终正确的 token 更值得学习。(p.6, S009)
4. 实验设置:任务、工具与训练规模
论文把评测分成三类:深度信息检索任务,包括 GAIA、Humanity's Last Exam、WebWalkerQA、XBench-DR 和 FRAMES;知识密集型 multi-hop QA,包括 2WikiMultihopQA、MuSiQue、Bamboogle、WebWalkerQA;以及数学 / 竞赛推理,包括 GSM8K、MATH、MATH500、AIME2024、AIME2025。(p.6, S010)
工具上,论文选择了三类代表性 agent 工具:Web Search Engine、Web Browser 和 Code Executor。训练实现使用 VERL,训练 batch size 为 128,PPO mini-batch size 为 16,上下文长度 20K;AEPO rollout 中 global rollout size 为 16,β=0.2,连续分支惩罚 P(l)=0.2·l;所有实验使用 16 张 NVIDIA H800 GPU。搜索引擎是 Bing Search API,US-EN 区域,每个 query 检索 10 个网页;深度信息检索场景中每页最多抽取 6000 tokens。(p.4, S005; p.6, S010)
5. 实验结果:AEPO 到底强在哪里?
5.1 深度信息检索:1K 样本训练出的强泛化
Table 1 是论文最核心的结果之一。Qwen3-14B + AEPO 在 WebWalkerQA / HLE / GAIA 上的 Pass@1 分别达到 43.0 / 11.2 / 47.6;Qwen3-8B + AEPO 也相对 ARPO 在 GAIA 和 WebWalkerQA 上有明显增益。作者强调这些结果来自 1K 开源 web search 训练样本,没有额外数据合成或过滤。(p.7, T001)
5.2 通用推理:不是只对 Web 搜索有效
Table 2 比较了 GRPO、Reinforce++、DAPO、GPPO、CISPO、GIGPO、ARPO 和 AEPO。AEPO 在 Llama3.1-8B-Instruct 上平均 56.3,在 Qwen2.5-7B-Instruct 上平均 60.3,均为表中最高。论文的解释是:agentic RL 的树状 rollout 本身有价值,但 AEPO 进一步解决了 rollout 分支和高熵梯度学习的问题。(p.8, T002)
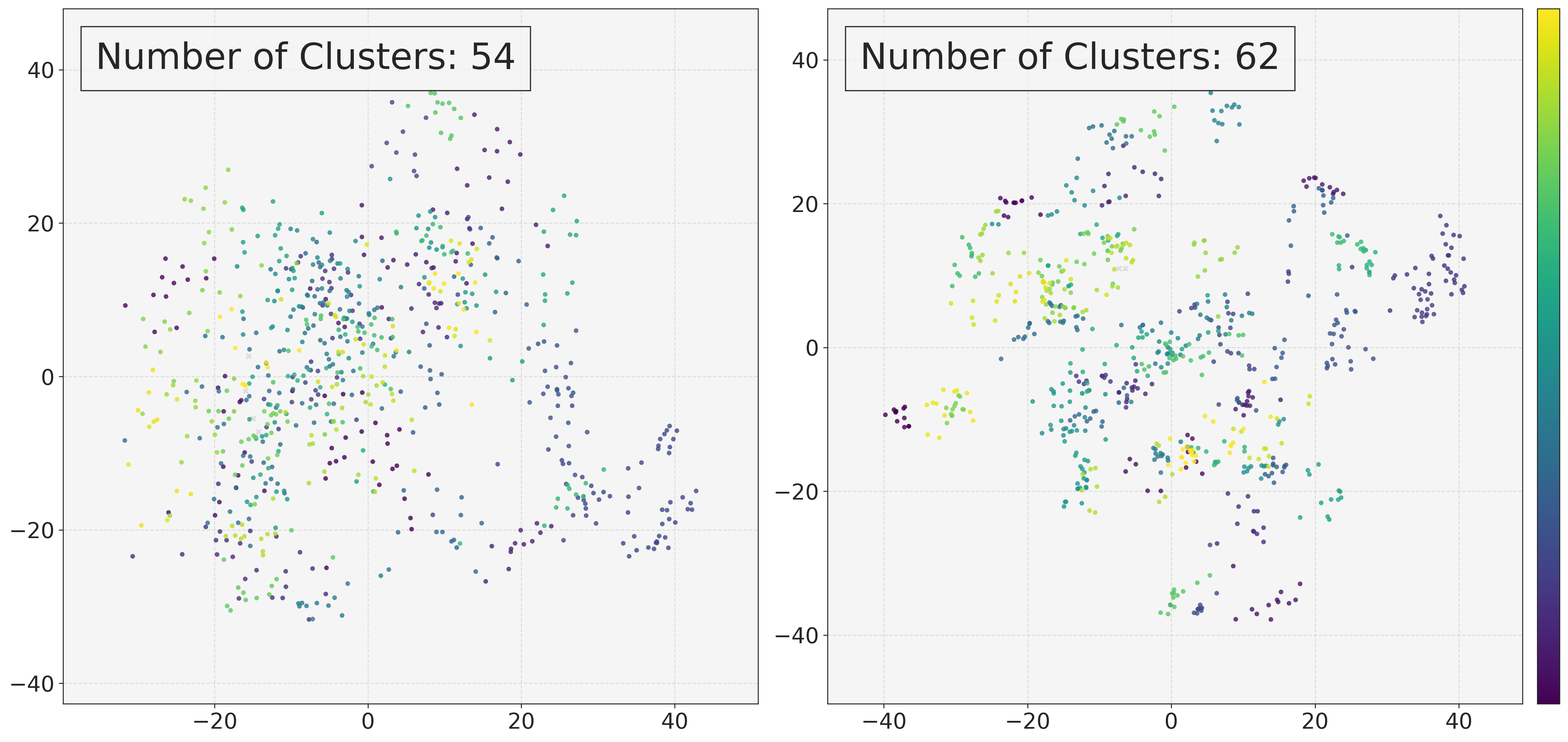
5.3 多样性:AEPO 是否真的缓解 rollout collapse?
作者随机抽取 10 个 rollout step,覆盖 640 个问题和约 7.6K 条轨迹,用 BGEM3 embedding、PCA 降维和 DBSCAN 聚类来分析 rollout 采样分布。相比 ARPO,AEPO 形成更多 cluster centers:62 vs 54,并呈现更大的类间间隔和更紧的类内距离。(p.9, S012)
5.4 稳定性:熵曲线不应该剧烈塌缩
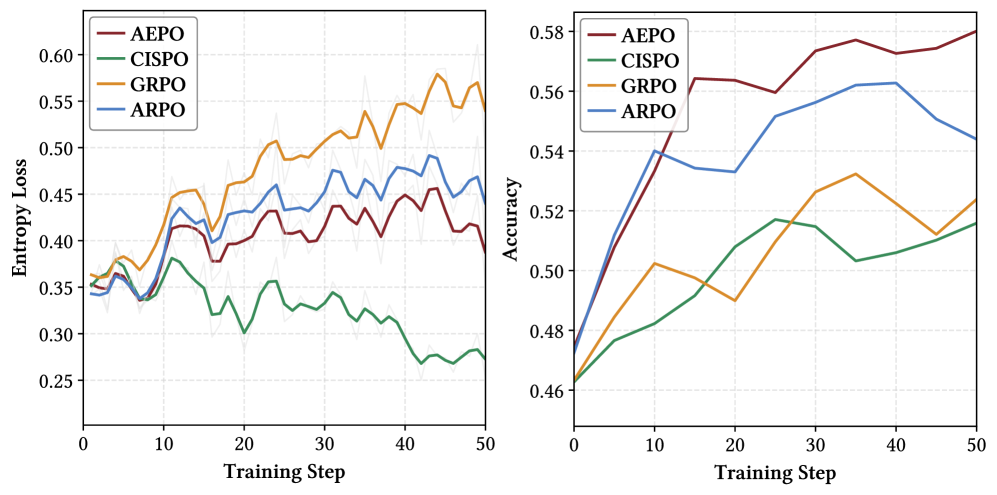
论文还画出了训练动态。作者观察到 clipping-optimized RL 在训练中容易出现熵不稳定,进而导致性能坍缩;AEPO 的 entropy curve 更平稳,准确率也更稳定提升。这里的结论很符合论文标题:目标不是把 entropy loss 推到某个极端,而是维持一种“足够高且稳定”的探索动态。(p.10, S013)
6. 我如何理解 AEPO:它在做“探索预算管理”
如果把 Web Agent 训练看成搜索问题,AEPO 的两部分其实对应两类预算:
- 采样预算:每个 query 有多少条 rollout、多少局部分支、哪些工具节点值得扩展。
- 梯度预算:哪些 token 的探索行为应该被学习,哪些只是随机波动或坏探索。
传统 agentic RL 很容易把这两个预算都交给“高熵”本身:哪里高熵就往哪里分支,哪个 token ratio 太大就按 clipping 处理。AEPO 的贡献是把高熵拆成两个判断:高熵是否值得继续采样?高熵 token 是否值得学习?前者由 entropy pre-monitoring 和 branch penalty 管,后者由 stop-gradient clipping balance 和 entropy-aware advantage 管。
与 GRPO / ARPO 的差异速记
- GRPO:主要解决 group relative advantage 的 policy optimization,缺少针对工具分支结构的 rollout 预算控制。
- ARPO:利用高熵工具步骤做 agentic branching,但可能把分支预算集中在少数连续高熵路径上。
- AEPO:继承 agentic branching 的收益,同时在 rollout 阶段控制分支覆盖,在 update 阶段保护有用高熵 token 的梯度。
7. 复现和落地时我会优先检查什么?
这篇论文的方向很实用,但如果要复现或放到自己的 Agent 框架里,我会优先关注以下风险:
entropy threshold 是否稳定?
不同 backbone、temperature、tool schema 会改变 token entropy 分布。论文给出 β=0.2 和 P(l)=0.2·l,但这些超参未必能直接迁移。
工具 observation 会污染 loss 吗?
论文明确在 loss 计算中排除 tool-call results 以避免 bias。实际系统里必须清楚区分模型 token、工具返回、环境注入文本。
搜索 API 与 browser agent 是隐藏变量
Bing 搜索区域、网页截断 6000 tokens、browser agent 的总结质量都会影响 rollout entropy 和最终 reward。
高熵 token 一定是好探索吗?
AEPO 通过正 advantage 条件和 entropy-aware advantage 过滤一部分噪声,但高熵仍可能来自格式不稳、工具 schema 混乱或无效反思。
8. 最小实现草图
如果先不完整复现论文训练,我会把 AEPO 的 rollout 思路实现成一个 agent runtime 采样器:
def aepo_rollout(query, model, tools, k, beta=0.2):
probe = run_one_tool_trajectory(query, model, tools)
h_root = entropy_of_initial_answer_or_plan(probe)
h_tool = mean_entropy_after_tool_calls(probe)
m = round(k * sigmoid(beta * (h_root - h_tool)))
branch_budget = k - m
pool = [run_global_trajectory(query, model, tools) for _ in range(m)]
consecutive = defaultdict(int)
while branch_budget > 0 and has_live_paths(pool):
path, step = select_high_entropy_tool_step(pool)
penalty = 0.2 * consecutive[path]
if should_branch(step.entropy_delta, penalty):
pool.extend(branch_from(path, step))
consecutive[path] += 1
branch_budget -= 1
else:
continue_path(path)
return poolpolicy update 部分则更依赖训练框架,需要在 GRPO / PPO loss 的 clipping term 与 advantage 计算中做改造。最容易踩坑的是 stop-gradient 的方向:forward 值要保持与原 clipping 形式一致,backward 才改变高熵 token 的梯度路径。(p.5-p.6, S009)
9. 深度理解 Q&A
Q1:AEPO 是不是简单把 entropy regularization 加大?
不是。论文反而强调“过度依赖熵信号”会导致训练问题。AEPO 不只是加熵正则,而是在 rollout 端用熵分配采样预算,在 update 端保护特定高熵 token 的梯度,并用 advantage 重新区分有用探索和无用不确定性。(p.2-p.6, S003-S009)
Q2:为什么高熵工具调用会连续出现?
工具调用会把新的网页、代码执行结果或错误信息注入上下文,下一步模型面对的信息状态更开放,因此可能继续不确定。论文统计中连续高熵工具轮占 56.5%,最长可达 6 轮,这就是 rollout collapse 的经验基础。(p.3, S003)
Q3:为什么不直接增加 rollout budget?
增加预算当然可能提升覆盖,但 Web 搜索和浏览有真实成本。论文 Figure 7 反而显示 AEPO 用约一半工具调用达到更好表现,说明问题不只是预算大小,而是预算是否花在不同候选路径上。(p.9-p.10, S013)
Q4:stop-gradient clipping balance 会不会鼓励坏探索?
有这个风险,所以 AEPO 不是保留所有高熵梯度。论文描述的是在 δ > 1 + ε_h 且 advantage 为正时保留并重缩放梯度;同时用 entropy-aware advantage 强化高熵但正确的 token。坏探索如果没有正向结果奖励,不应该被同等加强。(p.5-p.6, S009)
Q5:这篇论文对非 Web Agent 有启发吗?
有,但要看任务是否存在“昂贵工具调用 + 多轮探索 + 分支采样”。代码 agent、数据分析 agent、浏览器自动化 agent 都可能受益;纯单轮数学推理也可以借鉴高熵 token 梯度处理,但 rollout 预算部分的收益会小一些。
10. 总结:AEPO 的可迁移思想
AEPO 最值得带走的思想是:Agent 训练中的熵应该被当作资源调度信号,而不是无条件探索信号。在 rollout 阶段,高熵告诉我们哪里可能需要分支,但连续高熵也可能导致预算坍缩;在 policy update 阶段,高熵 token 可能是噪声,也可能是工具探索能力的关键载体,不能被 clipping 机制一刀切地丢掉。
对于 Web Agent RL,真正稀缺的不是“更多随机性”,而是把不确定性转化为覆盖更广、成本更低、梯度更有效的探索。
参考与出处
- Dong et al., Agentic Entropy-Balanced Policy Optimization, arXiv:2510.14545v1, 2025.
- 本文中的“论文图”均来自 arXiv HTML/PDF 原文,图片文件保存在
/assets/papers/aepo/;关键证据索引见/assets/papers/aepo/source_map.json。