Agent-R 论文精读:让语言 Agent 学会及时反思与纠错
解读 Agent-R 如何用 MCTS 构造修正轨迹,并通过迭代自训练让 LLM Agent 学会在交互任务中及时反思。
Paper Reading · arXiv:2501.11425
一句话:Agent-R 不再只教 Agent 走“全对轨迹”,而是教它在走错时尽早意识到错误,并接回正确路径。
论文:Agent-R: Training Language Model Agents to Reflect via Iterative Self-Training
作者:Siyu Yuan, Zehui Chen, Zhiheng Xi, Junjie Ye, Zhengyin Du, Jiecao Chen
机构:Fudan University, ByteDance Seed
版本日期:2025-03-25 · 链接:arXiv · PDF · Project / Code
适合读者:熟悉 ReAct、MCTS、AgentGym、SFT / DPO 或交互式 Agent 训练的读者。阅读时长约 20 分钟。
Expert trajectory 不教“犯错后怎么回来”
行为克隆强专家轨迹能教 Agent 做对动作,但训练数据通常是 all-correct trajectories;一旦真实交互中早期走错,模型缺少及时发现和修正错误的经验。(p.1-p.2, S001-S002)
用 MCTS 自动构造 revision trajectories
Agent-R 用 MCTS 搜索共享前缀后分叉的 bad / good trajectories,再把 bad path 截断到模型识别出的错误点,插入 revision signal,接上 good path。(p.5-p.6, S004-S007)
迭代自训练,让错误点越找越早
每轮用当前 actor model 重新判断 transition point、重收集 revision data,再混合 good trajectories 与通用数据做 SFT。随着迭代,Agent 学会更早纠错。(p.7, S008)
三类交互环境平均 70.71
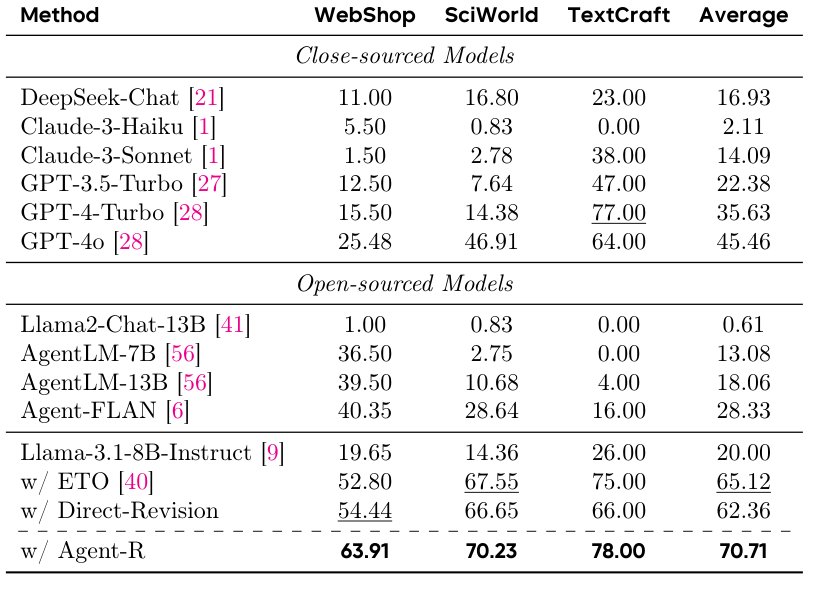
Llama-3.1-8B w/ Agent-R 在 WebShop、SciWorld、TextCraft 上平均 70.71,高于 ETO 的 65.12、Direct-Revision 的 62.36,也高于 GPT-4o 的 45.46。(p.9, T002)
我的快速判断
- 最值得带走的思想:Agent 训练不能只有“成功示范”,还需要“错误-反思-恢复”的过程数据。
- 最像工程可落地的点:把 MCTS / search logs 中的失败分支与成功分支拼成 revision trajectories,用 SFT 训练 Agent 的恢复能力。
- 最需要警惕的点:revision signal 是人工设计的模板;transition point 由当前模型判断,早期模型能力弱时可能引入噪声。
1. 这篇论文到底解决什么问题?
交互式 LLM Agent 面对的是长程、部分可观测、动作会改变环境状态的任务:网购页面上搜索和点击、ScienceWorld 中做科学实验、TextCraft 中按配方合成物品。和单轮问答不同,这类任务常常只有终止时才给 reward;中间某一步错了,环境未必马上告诉你。(p.3-p.4, S003)
传统训练方法往往依赖 expert trajectories 或 optimal trajectories:给模型看一条从头到尾都正确的路径,然后做行为克隆。这能提升完成率,但不一定让模型学会自我纠错。真实运行时,Agent 更常见的问题是:
- 早期走错路线,后面越走越远;
- 重复执行无效动作,卡在 dead loop;
- 直到最后失败才意识到不对,但已经来不及恢复。
Agent-R 的切入点正是:如果我们缺少人工 step-level critique,能否让模型自己从探索树中构造“我刚才错了,应该从这里改走另一条路”的训练样本?(p.1-p.2, S001-S002)
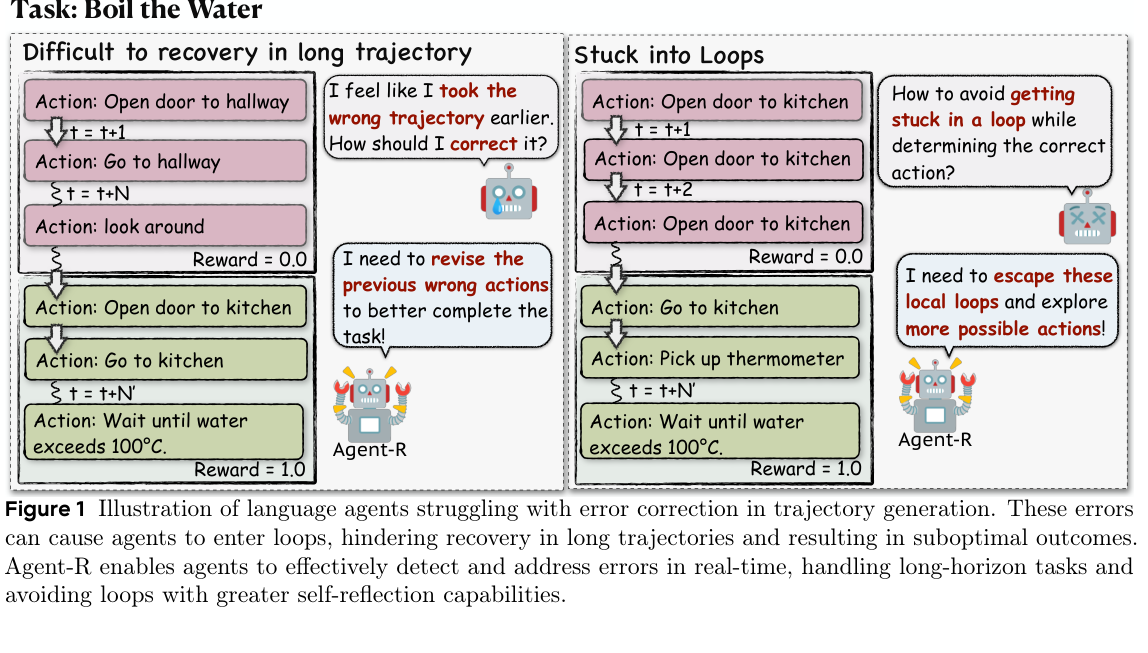
2. 方法总览:Agent-R 的两阶段循环
Agent-R 包含两个阶段:(p.4-p.7, S004-S008)
- Phase I: Model-Guided Reflection Trajectory Generation。用 MCTS 搜索 action tree,收集 bad trajectories 与 good trajectories;再让当前 actor model 判断 bad trajectory 中第一个错误 action,构造 revision trajectory。
- Phase II: Iterative Self-Training with Revision Trajectories。把 revision trajectories、good trajectories 与通用对话数据混合,做 supervised fine-tuning;下一轮再用更新后的 actor model 重做数据构造。

3. Revision trajectory:这篇论文最关键的数据结构
论文定义了四类轨迹:(p.5, S005)
- Initial trajectory
τi:bad 与 good path 共享的前缀。 - Bad trajectory
τb:从共享前缀后走向低 reward 或失败结果的动作序列。 - Good trajectory
τg:从同一前缀后走向高 reward 或成功结果的动作序列。 - Revision trajectory
τr:先保留 bad path 到错误点t',插入 revision signalrs,再接上 good path 的后半段。
用简化形式写:
initial prefix: τi
bad suffix: ... bad action ... bad observation ...
good suffix: ... good action ... good observation ...
revision trajectory:
τi + bad actions until transition point t'
+ rs: "I made an error. I must determine how to correct it."
+ good actions after the corresponding branch这样构造出来的数据会告诉模型三件事:第一,什么样的历史状态可能是错的;第二,如何显式表达反思;第三,反思后应该怎样继续行动。相比只看成功轨迹,这更接近真实 Agent 的恢复过程。
4. MCTS 如何帮 Agent-R 自动造数据?
Agent-R 用 MCTS 在交互环境中探索 action tree。每个节点代表一个历史状态;selection 阶段用 UCT 平衡探索与利用;simulation 阶段 rollout 到终止状态,拿环境 reward;backpropagation 回传价值。(p.6, S006)
UCT 写作:
UCT(s) = Q(s) + c_uct * sqrt(log N_parent(s) / N(s))其中 Q(s) 是状态平均 reward,N(s) 是访问次数,N_parent(s) 是父节点访问次数,c_uct 控制探索强度。实验中每个 Monte Carlo estimation 采样 k=8 个 rollout,深度 d=20,每个深度生成 4 个候选 action,c_uct=0.25。(p.9, S006)
MCTS 的好处是:它天然会产生同一前缀下的不同后续路径。有些后续高 reward,有些低 reward;这正好可以组成 bad/good pair,再转成 revision trajectory。
5. 为什么不能简单 Direct-Revision?
论文比较了一个直接 baseline:把 t' 设在 bad trajectory 的终点,也就是等整条失败轨迹走完,再接一句反思,再拼上 good path。这叫 Direct-Revision。(p.6, S007)
问题是,交互式 Agent 需要的是及时修正。如果早在第 3 步就犯了灾难性错误,却在第 20 步失败后才说“我错了”,模型学到的是“失败后总结”,不是“运行中发现错误”。Agent-R 因此让 actor model 自己检查 bad trajectory 中的每个 action,找出它当前能力范围内识别到的第一个错误 action,并把 transition point 放在那里。(p.6-p.7, S007)
这个设计也解释了为什么 Agent-R 要迭代:早期 actor model 可能只能识别很晚的错误;训练几轮后,模型反思能力增强,就能把 transition point 往前推,学到更早纠错。
6. 训练目标:revision + good + general data
只用 revision trajectories 可能有冷启动问题,因为模型一开始未必知道正确路径是什么。Agent-R 因此混合三类数据:(p.7, S008)
- Good trajectories:帮助模型学习环境中的高 reward 行为。
- Revision trajectories:帮助模型学习错误识别和恢复。
- General dataset:论文使用 ShareGPT 风格通用数据,以保持泛化能力。
训练损失可以理解为:
L(θ) = η * [ log P(good trajectory | instruction)
+ log P(revision signal + good suffix | instruction, bad prefix) ]
+ (1 - η) * log P(general answer | general input)实验中设置 η=0.2。此外,论文逐轮提高好轨迹门槛 α:iteration 1 为 0.5,iteration 2 为 0.7,iteration 3 为 1.0。直觉上,这是先允许“还不错”的 good trajectories 帮模型起步,再逐步逼近 optimal trajectories。(p.8, S008-T001)
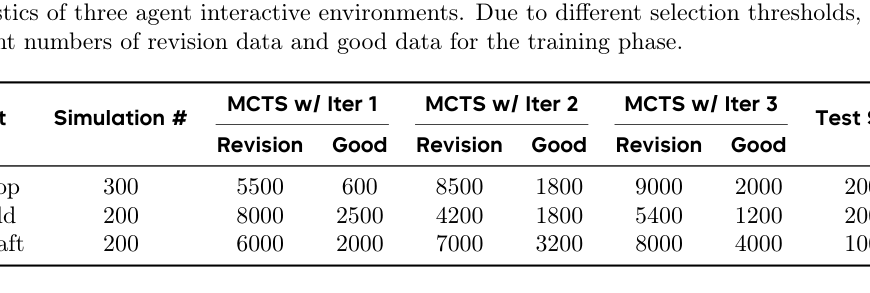
7. 实验:Agent-R 在三类交互环境上是否有效?
论文在 AgentGym 平台的三个环境上评估:(p.8-p.9, T001-T002)
- WebShop:在线购物环境,Agent 需要搜索商品、点击页面、选择满足需求的商品。
- ScienceWorld / SciWorld:科学文本环境,考察科学推理和实验操作。
- TextCraft:Minecraft 合成文本环境,Agent 需要根据配方树合成目标物品。
主模型是 Llama-3.1-8B-Instruct。SciWorld 与 WebShop 用 average final reward,TextCraft 用 success rate;三类环境最大轮数都是 100。对比对象包括 GPT-4o、GPT-4-Turbo、Claude、DeepSeek-Chat、AgentLM、Agent-FLAN、ETO 和 Direct-Revision。(p.9, T002)
8. 结果怎么读:revision data 甚至优于 optimal trajectories
Figure 3 是我认为最关键的实验之一。它比较了 Agent-R、Direct-Revision、只用 Optimal Trajectory、Optimal + Good Trajectory 在三轮迭代中的表现。整体趋势是:Agent-R 随迭代持续上升,并且在后期明显优于只训练 optimal path 的方法。(p.10, F003)
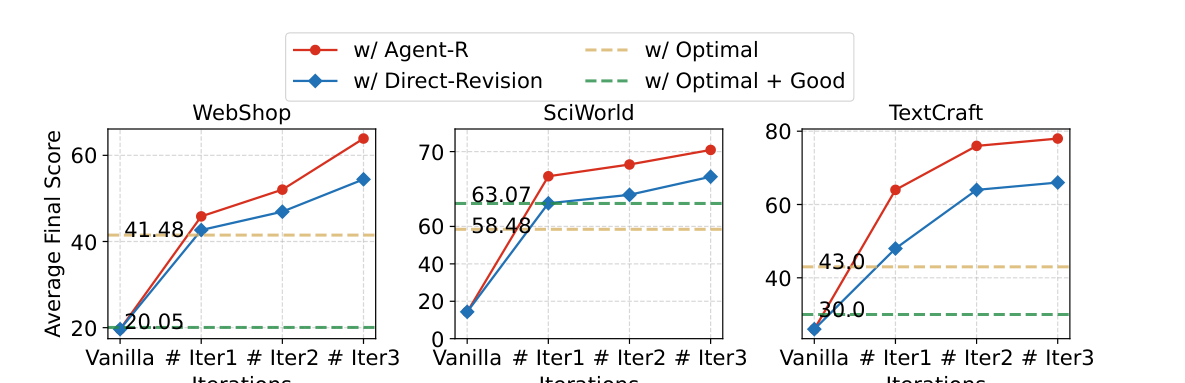
为什么会这样?我的理解是:optimal trajectories 只覆盖成功路径分布;但 Agent 自己运行时会落入大量非 optimal 状态。Revision trajectories 恰好覆盖了这些 off-distribution 状态,并告诉模型如何从这些状态返回高 reward 区域。这和机器人/游戏里的 recovery policy 很像:只模仿专家不够,还要知道摔倒后怎么站起来。
9. Agent-R 真的提升了自反思能力吗?
为了专门评估 self-reflection,论文收集 Llama-3.1-8B-Instruct 在测试集上的失败轨迹,随机截断到某个时间步,再让不同模型继续行动,看能否把失败轨迹修回更高 reward。Table 3 显示,Llama-3.1-8B w/ Agent-R 第三轮平均 46.75,高于 Direct-Revision 第三轮的 35.67,也显著高于 ETO、Optimal、GPT-4o 等设置。(p.11, T003)
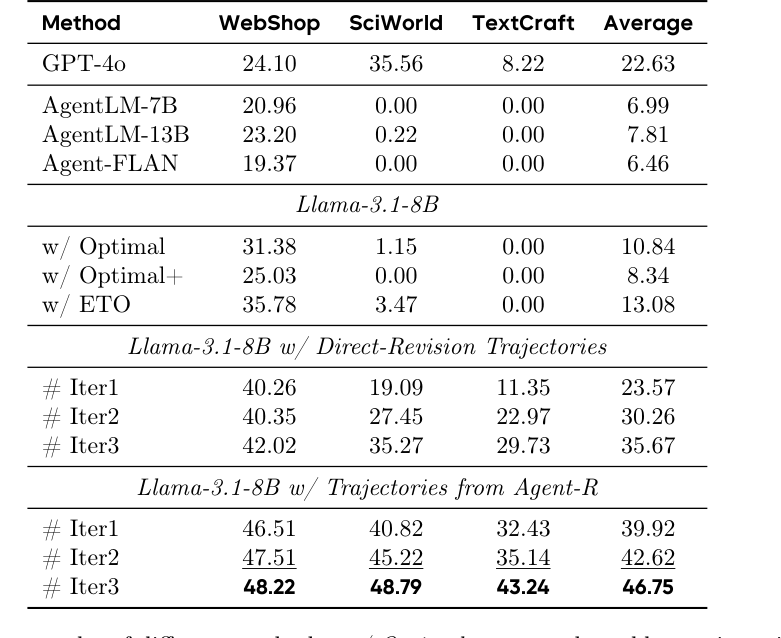
10. 两个行为证据:更少循环,更早纠错
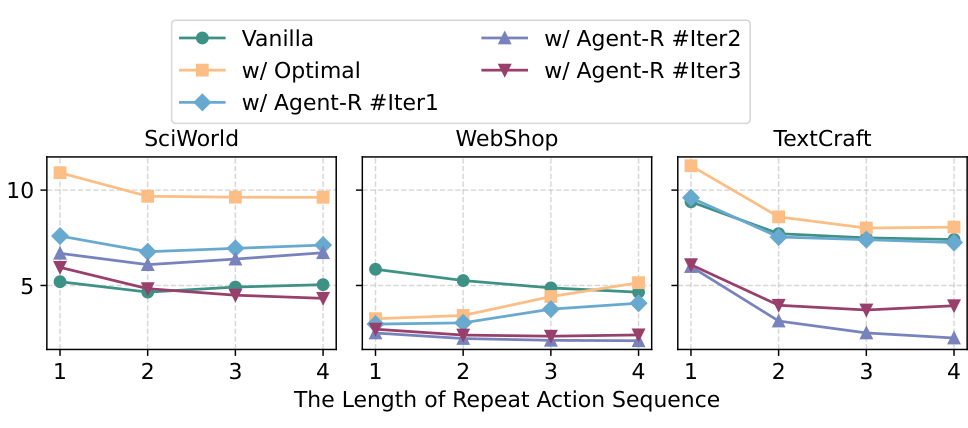
10.1 更少 dead loops
论文统计测试轨迹中的 repeated action sequence。结果显示,即使 MCTS 能产生 optimal trajectories,这些轨迹中仍可能有重复或噪声中间动作;只学 optimal path 可能让 Agent 学到局部循环。相比之下,Agent-R 的 revision trajectories 明确包含“发现循环并跳出”的信号,因此能减少 dead loops。(p.12-p.13, F004)
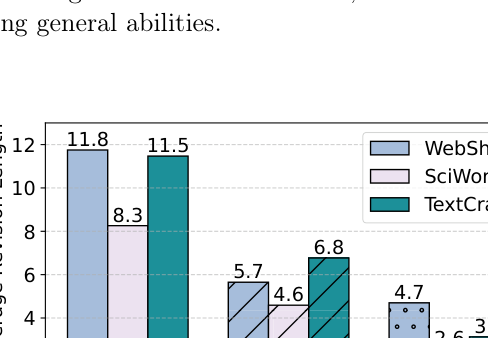
10.2 更早发现错误
论文用 revision length 衡量模型从 bad trajectory 开始到识别第一个错误 action 之间的动作数。长度越短,说明模型越早发现问题。Figure 5 显示 Agent-R 迭代后 revision length 明显下降:WebShop 从 vanilla 11.8 降到 Iter2 的 4.7;SciWorld 从 8.3 降到 2.6;TextCraft 从 11.5 降到 3.1。(p.12, F005)
11. 多任务训练为什么更适合 Agent-R?
论文还比较了 single-task training 与 multi-task training。Figure 6 与附录 Table 6 显示,在后期迭代中,Agent-R 的 multi-task training 优于 single-task training;第三轮 Agent-R multi-task 平均 70.71,而 single-task 平均 67.96。作者认为,Agent-R 生成的 revision trajectories 更适合跨任务迁移,因为“发现错误、跳出循环、接回正确路径”是一种相对通用的交互能力。(p.13, F006; p.23, T006)

12. 我对 Agent-R 的理解:它训练的是 recovery policy
Agent-R 的贡献不只是“用 MCTS 造数据”。更准确地说,它把交互式 Agent 的训练目标从:
模仿专家:在好状态下做对动作
扩展为:
恢复策略:在坏状态下识别错误,并切换到更好的动作序列
这对真实 Agent 系统非常重要。因为线上 Agent 很少一直处于 expert trajectory 上;它会遇到搜索无结果、网页状态变化、动作无效、观察和计划不一致等非理想状态。Agent-R 通过 bad/good branch 拼接,显式把这些非理想状态纳入训练分布。
Agent-R 最有价值的思想是:不要只收集成功案例,也要系统性收集“失败在哪里发生、如何意识到失败、如何恢复”的案例。
13. 局限与我会继续追问的问题
transition point 判断是否可靠?
Agent-R 依赖当前 actor model 找第一处错误。早期模型能力弱时,可能找晚、找错或漏掉真正的因果错误。论文用迭代训练缓解,但这仍是噪声来源。
revision signal 会不会模板化?
附录列出 10 条人工 revision thoughts。它们能提供稳定格式,但也可能让模型学会“说一句反思模板”而不真正理解错误。更好的做法可能是结构化错误类型和证据。
MCTS 成本如何扩展?
实验中每个估计 k=8 rollouts、深度 20、每步 4 个候选 action。对真实浏览器/代码 Agent,MCTS 环境交互成本可能很高,需要日志复用或离线搜索。
good path 接 bad prefix 是否总是状态一致?
如果 bad action 已经不可逆地改变环境,把 good suffix 接上可能不再合法。论文通过共享 parent node 和 reward 约束降低风险,但在强状态依赖任务中仍需校验。
14. 工程启发:如何把 Agent-R 思想落到自己的 Agent 系统?
我会优先实现一个日志驱动版本:
1. 记录每次 Agent rollout:
- instruction
- action / observation history
- terminal reward
- repeated action patterns
- invalid action / mismatch observation / irrelevant action tags
2. 从同一任务或相似状态中挖掘 bad/good pairs:
- same prefix or similar environment state
- bad suffix has low reward or loop
- good suffix has higher reward
3. 构造 revision sample:
- bad prefix until detected error
- structured reflection:
error_type, evidence, why_bad, next_strategy
- good continuation
4. 训练时混合:
- success demonstrations
- recovery demonstrations
- general instruction data
5. 评估不要只看 final score:
- recovery rate from failed prefixes
- average revision length
- repeated action sequence count
- invalid action rate这样即使暂时不跑完整 MCTS,也能先验证“recovery data 是否比 pure expert data 更能提升线上稳定性”。
参考与出处
- Yuan et al., Agent-R: Training Language Model Agents to Reflect via Iterative Self-Training, arXiv:2501.11425, version date 2025-03-25.
- 论文 PDF:https://arxiv.org/pdf/2501.11425;项目页:https://github.com/bytedance/Agent-R。
- 本文图表均为论文原图裁剪;source map 存放于
/assets/papers/agent-r-2501-11425/source_map.json。 - 文中的 Sxxx / Fxxx / Txxx 指向本地 source map 中的段落、图和表。