ARPO 论文精读:为什么 Agent RL 要在工具调用后分叉探索
解读 ARPO 如何用工具调用后的高熵信号做自适应 rollout,并用 advantage attribution 训练多轮工具型 Agent。
Paper Reading · arXiv:2507.19849
一句话:ARPO 把 Agent RL 的探索重点,从“整条轨迹多采几遍”移动到“工具反馈后最不确定的几步”。
论文:Agentic Reinforced Policy Optimization
作者:Guanting Dong, Hangyu Mao, Kai Ma, Licheng Bao, Yifei Chen, Zhongyuan Wang, Zhongxia Chen, Jiazhen Du, Huiyang Wang, Fuzheng Zhang, Guorui Zhou, Yutao Zhu, Ji-Rong Wen, Zhicheng Dou
机构:Renmin University of China, Kuaishou Technology
日期:2025-07-26 · 链接:arXiv · PDF · Code
适合读者:熟悉 RLVR / GRPO、ReAct、搜索增强 Agent、tool-use training 的读者。阅读时长约 20 分钟。
Trajectory-level RL 太粗
现有 RLVR 往往把完整轨迹当成采样单位:答案对了就整条轨迹增益,错了就整条轨迹受罚。但多轮工具型 Agent 的关键行为常发生在某次搜索、浏览或代码执行之后。(p.1-p.2, S001-S002)
工具反馈后 10-50 个 token 熵会飙升
论文的先导实验发现,工具调用后的短窗口里 token entropy 明显上升;搜索反馈比 Python 输出更不确定。这给“在哪里加大探索”提供了可测信号。(p.4, S003)
高熵处局部分叉,而不是全程重采样
ARPO 先保留一部分全局 rollout,再把剩余预算留给工具调用后的局部分支:当 P_t = α + β·ΔH_t 超过阈值,就从当前节点 Branch 出多条后续路径。(p.5, S005-S006)
13 个 benchmark + 约一半工具预算
论文报告 ARPO 在计算推理、知识推理和 deep search 共 13 个 benchmark 上优于 trajectory-level RL,并在 Qwen2.5-7B 对比中用约一半工具调用达到更高总体准确率。(p.9-p.11, T001-T002, S011)
我的快速判断
- 最有启发的点:把 token entropy 当作 Agent 训练中的“局部探索路标”,比盲目增加完整轨迹数更贴近工具调用任务的结构。
- 最值得复现的模块:adaptive rollout + shared/individual advantage accounting。哪怕不用完整 ARPO,也可以先在日志里记录 post-tool entropy 和分支收益。
- 最需要警惕的风险:高熵并不总等于有价值探索;它也可能只是搜索结果噪声、网页污染、格式漂移或模型困惑。
1. 这篇论文到底解决什么问题?
ARPO 关注的是 LLM-based tool-use agent 的 RL 训练。这类 Agent 在推理中会穿插外部工具反馈:搜索引擎返回网页摘要,浏览器 Agent 抽取页面内容,代码解释器返回运行结果或报错。问题在于,常见 trajectory-level RL 算法主要比较整条轨迹的最终奖励,很难回答一个更细的问题:到底是哪一次工具反馈之后的哪几步,决定了后续轨迹质量?(p.1-p.2, S001-S002)
论文的核心诊断是:工具反馈会改变模型接下来生成 token 的分布。外部信息进入上下文后,模型既可能获得关键证据,也可能面对互相冲突、噪声很大或格式陌生的信息。若仍然只在完整轨迹层面采样,训练预算会浪费在低价值位置;真正该探索的,是那些工具调用后不确定性突然升高的节点。(p.4, S003)
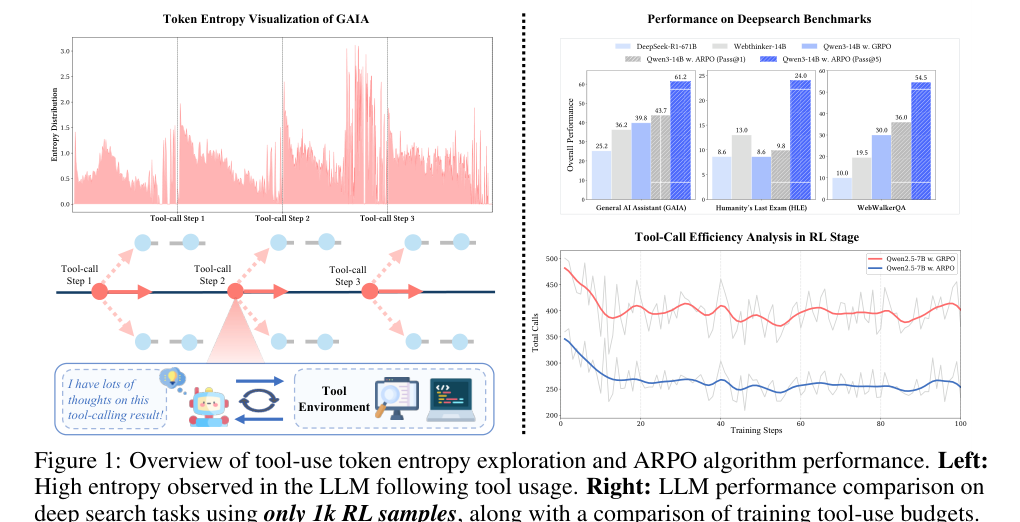
2. 关键观察:工具调用后的熵是一个训练信号
论文先定义 token entropy:在第 t 步,根据当前上下文得到词表分布 p_t,计算 H_t = -Σ_j p_{t,j} log p_{t,j}。注意,这里的熵不是某个 token 本身“对不对”,而是整个下一 token 分布的不确定程度。(p.3, S003)
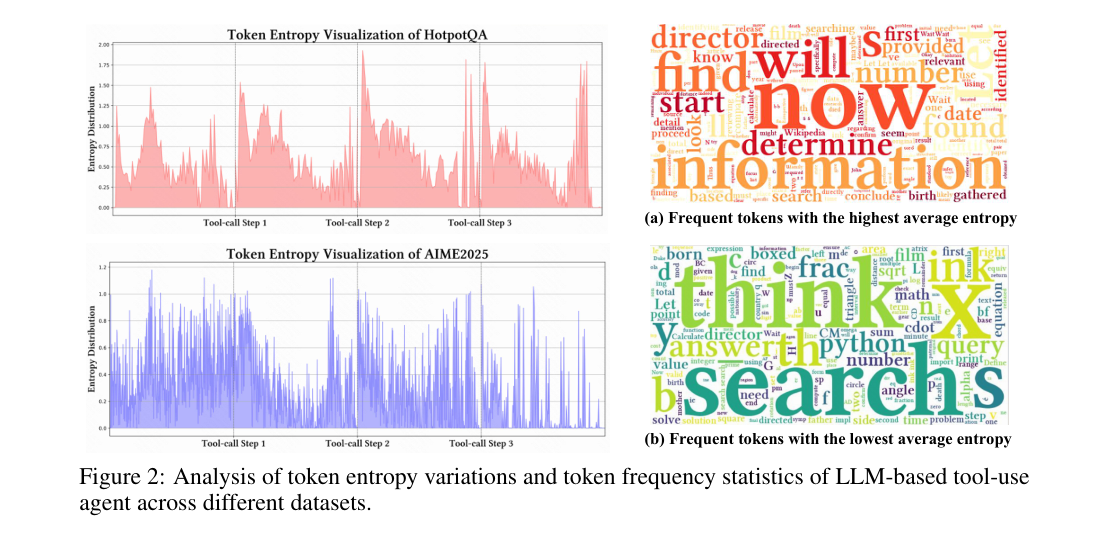
作者比较了搜索型 Agent 与 Python 解释器型 Agent,得出三个观察:
- Ob.1:每次工具调用后的前 10-50 个 token,entropy 会快速上升。
- Ob.2:推理早期 entropy 也会上升,但通常低于工具反馈后的上升。
- Ob.3:搜索反馈比 Python 反馈带来更大 entropy;直觉上,网页文本更开放、更噪,Python 输出更确定。
这一步很重要,因为它把“什么时候应该多探索”从经验规则变成了可观测量。ARPO 后续所有设计都围绕这个信号展开。(p.4, S003-S004)
3. ARPO 方法总览:全局 rollout + 工具后局部分叉
ARPO 的训练流程可以拆成三层:
- Rollout Module:策略模型与工具环境交互,得到带工具反馈的推理轨迹。
- Entropy-based Adaptive Rollout:一部分预算用于完整轨迹,另一部分预算保留给高熵工具调用后的局部分支。
- Advantage Attribution Estimation:因为局部分支共享前缀、后续不同,所以需要分别处理共享 token 与分支 token 的优势归因。
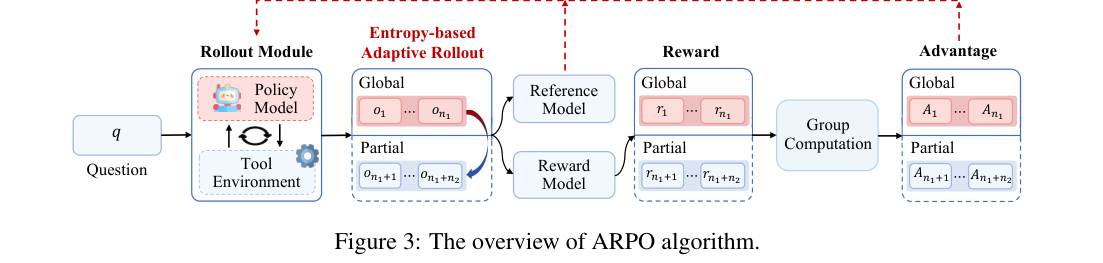
3.1 Entropy-based Adaptive Rollout
给定全局 rollout size M,ARPO 不会把 M 全部用于完整轨迹,而是先生成 N 条全局轨迹,把 M-N 留给 partial sampling。具体步骤如下:(p.5, S005-S006)
1. Rollout initialization
- sample N full trajectories
- reserve M - N budget for partial branches
- compute initial entropy H_initial from first k tokens
2. After each tool call
- generate k additional tokens
- compute H_t
- calculate ΔH_t = Normalize(H_t - H_initial)
3. Adaptive beaming
- P_t = α + β · ΔH_t
- if P_t > τ: Branch(Z) from this tool-call node
- else: continue the current trajectory
4. Termination
- stop branching when partial budget is exhausted
- if branches terminate early, supplement with full trajectories这个设计的直觉很清楚:完整轨迹采样负责保留全局多样性;局部分支采样负责在“刚拿到工具反馈、模型最不确定”的位置展开细查。论文还声称,在忽略 entropy 计算小开销时,ARPO 可把 rollout 复杂度从 trajectory-level RL 的 O(n^2) 降到 O(n log n) 到 O(n^2) 之间。(p.6, S006)
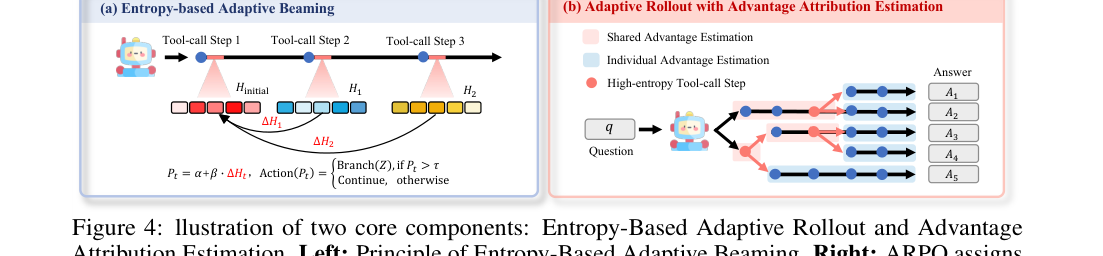
ΔH_t 判断是否分叉;右侧展示分叉轨迹中的共享段与个体段。读图重点:一旦从中间节点分叉,后续 RL 更新就不能再把每条轨迹当作完全独立样本处理。(p.6, F004; S006-S007)3.2 Advantage Attribution:共享前缀不能乱背锅
局部分支带来一个信用分配问题:多条分支可能共享同一段前缀 token,但最终 reward 不同。若直接把每条分支当作独立轨迹更新,共享前缀会被重复、甚至矛盾地赋值。ARPO 因此讨论两种 advantage attribution:(p.6-p.7, S007)
- Hard Advantage Estimation:显式区分 shared tokens 和 individual tokens。分支独有 token 使用各自 reward 归一化优势;共享 token 使用包含该共享段的多条轨迹优势均值。
- Soft Advantage Estimation:沿用 GRPO 目标函数,通过 importance sampling ratio 的一致性,让共享前缀在优化中隐式获得对齐的优势信号。
论文 Figure 5 对比显示,soft setting 在 RL 训练中 reward 更高且更稳定,所以 ARPO 默认采用 soft advantage estimation。(p.7, S007)
3.3 Reward:正确性、格式与多工具协作
奖励函数来自 Tool-Star 风格的层级设计:格式正确且答案正确时给 correctness reward;格式正确但答案错误给 0;格式不对给 -1。额外地,如果模型在正确答案和正确格式下同时使用 <search> 与 <python>,会得到 r_M = 0.1 的多工具协作奖励。(p.7, S008)
这里有一个工程注意点:多工具 bonus 可以鼓励复杂任务中的协作,但也可能让模型在不必要时“为了拿分而多调用工具”。因此真实系统复现时,最好同时记录工具成本、无效工具率和任务类型,而不是只看最终准确率。
4. 实验设置:哪些任务证明了它有效?
论文评估 13 个 benchmark,覆盖三类场景:(p.8, S009)
- Mathematical Reasoning:AIME2024、AIME2025、MATH500、MATH、GSM8K。
- Knowledge-Intensive Reasoning:WebWalker、HotpotQA、2WikiMultihopQA、MuSiQue、Bamboogle。
- Deep Search:GAIA、WebWalkerQA、Humanity's Last Exam、xbench-DeepSearch。
训练上,作者先用 LLaMAFactory 做 cold-start SFT:Tool-Star 54K 样本,加 STILL 0.8K 数学数据;RL 阶段深度推理用 Tool-Star 10K,deep search 只用 1K 来自 SimpleDeepSearcher 与 WebSailor 的 hard search 混合样本。搜索结果采用 Bing top-10 snippets,代码解释器在 sandbox 中运行,QA 正确性使用 token-level F1 或 LLM-as-judge。(p.8-p.9, S009)
5. 主结果:ARPO 是否真的比 GRPO / DAPO 更好?
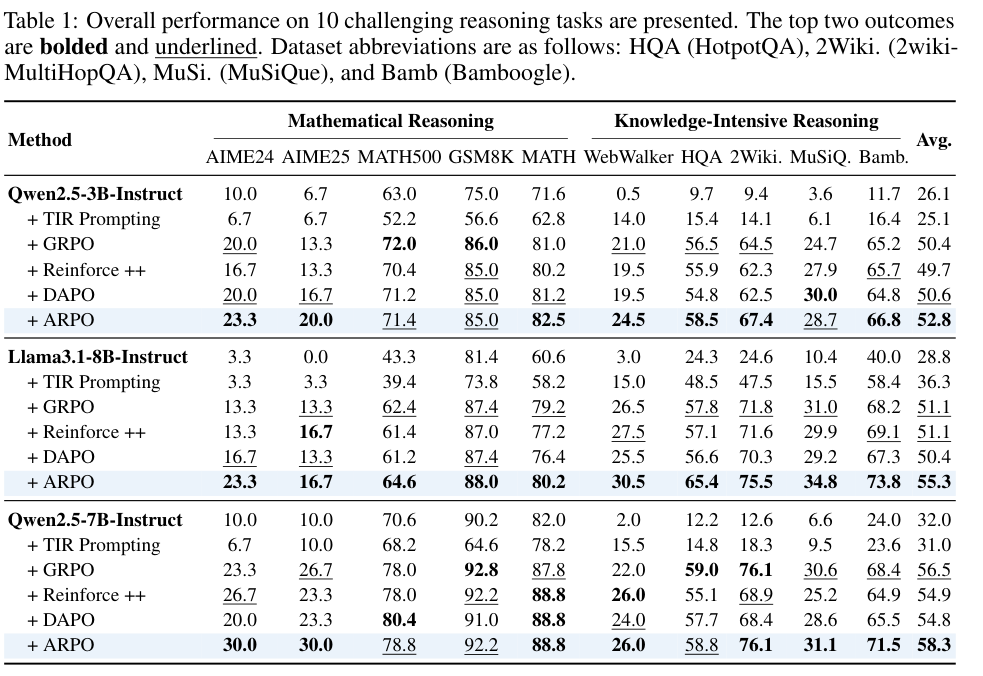
在数学与知识密集推理任务上,表 1 的重点不是某一个单项冠军,而是三种 backbone 的平均结果。Qwen2.5-3B、Llama3.1-8B、Qwen2.5-7B 加 ARPO 后平均分分别为 52.8、55.3、58.3,整体高于 GRPO、Reinforce++ 与 DAPO。(p.9, T001)
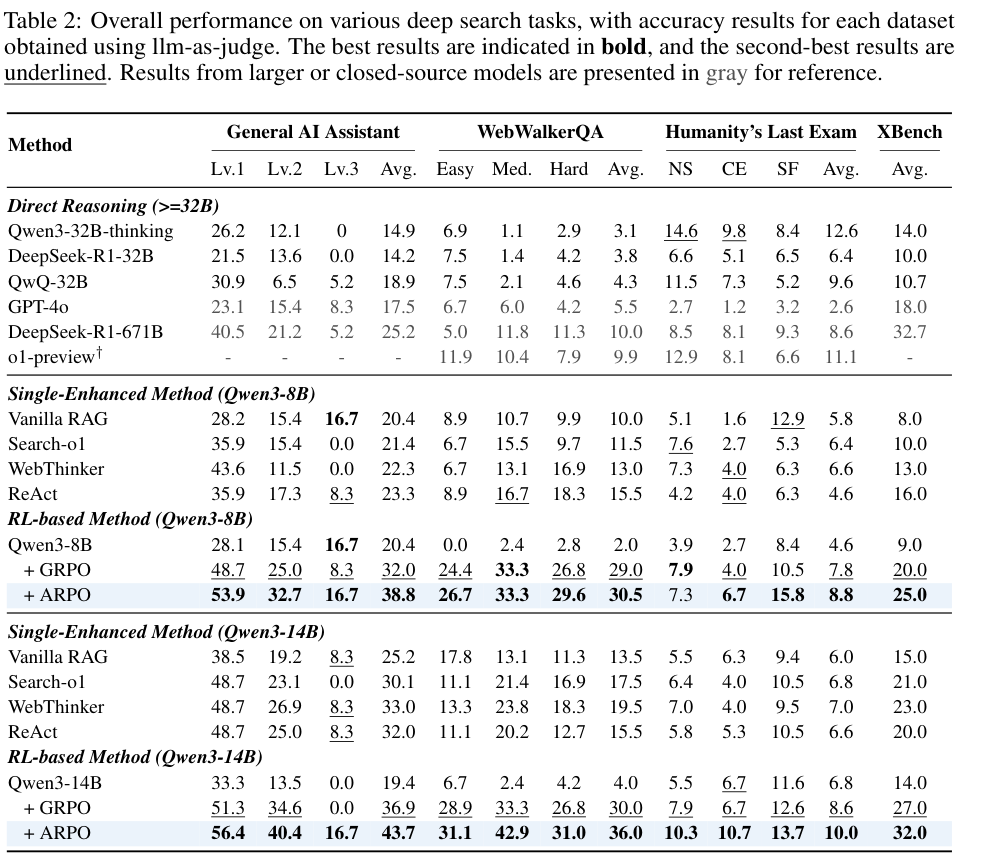
Deep search 的表 2 更能体现 Agent 场景。Qwen3-8B + ARPO 在 GAIA、WebWalkerQA、HLE、XBench 上平均为 38.8 / 30.5 / 8.8 / 25.0;Qwen3-14B + ARPO 为 43.7 / 36.0 / 10.0 / 32.0。作者强调,ARPO 在 RL 阶段只用了 1K hard search 样本,却能在 GAIA / WebWalkerQA 上相对 GRPO 获得约 6% 的提升。(p.10, T002)
6. 进一步分析:Pass@K、工具成本与浏览器能力
6.1 Pass@K:分叉提升了采样空间
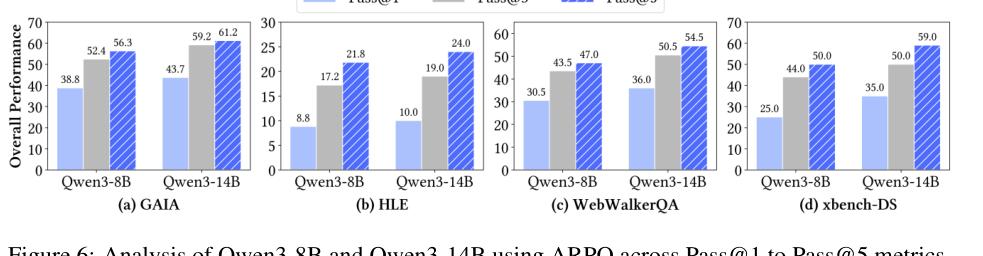
由于 deep search 是动态多轮任务,Pass@1 不能完全反映模型的工具使用潜力。论文继续看 Pass@3 / Pass@5,发现 Qwen3-14B + ARPO 在 Pass@5 下达到 GAIA 61.2%、HLE 24.0%、xbench-DR 59.0%。这说明 ARPO 不只是提高单次答案,还增加了高质量工具路径的采样多样性。(p.11, S010)
6.2 工具调用效率:更强不一定更贵
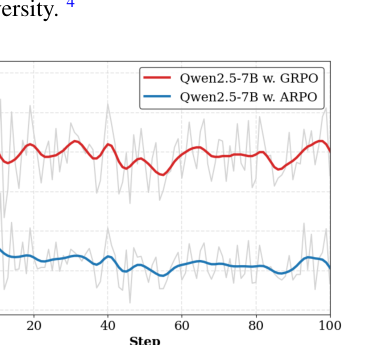
工具调用是 Agent RL 的真实成本中心:搜索 API、浏览器解析、代码沙箱都会花钱花时间。论文在 Qwen2.5-7B 上比较 ARPO 与 GRPO,发现 ARPO 总体准确率更高,同时工具调用数约为 GRPO 的一半。作者把原因归结为:ARPO 只在高熵工具调用步骤展开探索,而不是全轨迹反复采样。(p.11, S011)
6.3 浏览器消融:外部工具本身也很关键
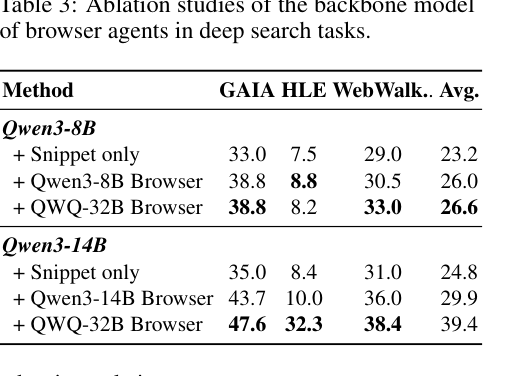
论文还做了 browser agent 消融:只用 snippet 最弱,同规模浏览器更好,更大的 QWQ-32B browser 通常进一步提升。例如 Qwen3-14B + QWQ-32B Browser 在 GAIA/HLE/WebWalker/Avg 上为 47.6 / 32.3 / 38.4 / 39.4。这提醒我们,ARPO 优化的是 agentic policy,但系统上限仍强依赖外部工具质量。(p.11, T003)
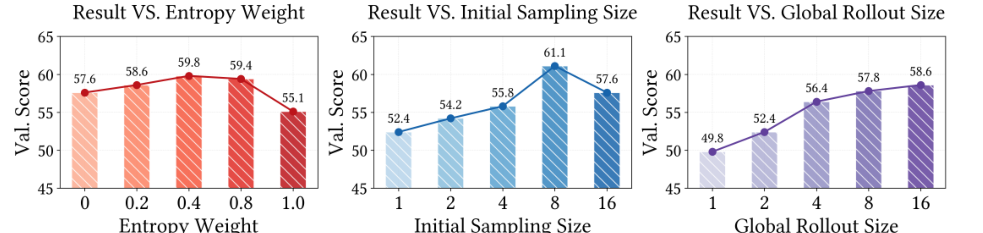
7. 超参:熵权重、初始采样数、全局 rollout size 怎么选?
论文用 Qwen2.5-7B 分析三个超参:(p.12, S012)
- Entropy Weight:验证分数随熵权重上升先提高,在 0.4 附近达到峰值;到 1.0 时下降,说明过度依赖熵会伤害采样多样性。
- Initial Sampling Size N:从 1 增到 8 时性能提升,N=8 最优;当全局 rollout size 为 16 时,N=8 对应全局:局部约 1:1。N=16 退化成完全全局采样,性能反而下降。
- Global Rollout Size M:M 越大整体越好,说明 ARPO 在更大采样预算下仍可扩展。
8. 我对 ARPO 的理解:它更像一种 Agent 训练资源调度器
如果把 GRPO / DAPO 看成“如何根据一组完整回答更新策略”,ARPO 更像是在问另一个问题:同样的采样预算,应该花在哪些时间点? 它把 rollout 预算拆成两类:
- global budget:用于覆盖不同完整解题路线,避免过早锁死在一个思路。
- partial budget:用于在工具反馈后的不确定位置展开多条局部后续路径。
这个视角很适合 Agent,因为工具反馈天然形成了“决策边界”:搜索结果返回了,下一步是继续搜、打开页面、写代码验证、还是总结答案?这些节点比普通 token 位置更值得探索。ARPO 的贡献就是把这种边界用 entropy 检测出来,并把 RL 更新中的 shared prefix / branch path 处理清楚。
ARPO 最值得带走的思想不是某个公式,而是:Agent RL 的探索单位不必总是完整轨迹;工具调用后的局部状态,可能才是最该分配训练预算的地方。
9. 局限与我会继续追问的问题
高熵一定代表值得探索吗?
不一定。高熵也可能来自网页噪声、搜索结果不相关、上下文格式混乱或模型能力不足。实际系统中应把 entropy 与工具结果质量、检索置信度、历史成功率结合。
外部工具配置影响多大?
Table 3 已经说明 browser agent 强弱会显著影响 deep search。若换搜索引擎、网页解析器、代码沙箱或 judge,ARPO 的绝对收益可能变化。
多工具 bonus 会不会诱导滥用工具?
奖励里对同时使用 search 与 python 给 0.1 bonus,可能在复杂任务上有益,但也可能鼓励不必要调用。复现时应统计无效工具调用与平均成本。
partial rollout 的实现复杂度如何?
从中间节点分叉意味着需要保存工具状态、上下文前缀、采样树和 advantage 映射。训练框架若原本只支持完整 responses,需要改造数据结构。
10. 工程启发:如果我要把它放进 Agent 框架
我会先实现一个观测与离线分析版本,而不是直接改 RL:
1. 在每次 tool_call 后记录:
- tool type: search / browser / python / other
- returned content length and confidence
- next k token entropy H_t
- final outcome reward
2. 构建 post-tool decision dataset:
- shared prefix
- branch candidates
- branch-level reward / cost
- whether branch changed final answer
3. 先做离线策略:
- only branch when ΔH_t is high and tool output is credible
- cap branch count per question
- log cost-normalized reward
4. 再进入 RL:
- global samples preserve diversity
- partial samples target high-uncertainty tool nodes
- shared prefix and branch tokens use separated advantage accounting这样可以先验证一个核心假设:在你的任务、工具和模型上,post-tool entropy 是否真的能预测“值得分叉探索”的节点。如果相关性弱,直接套 ARPO 可能只会增加系统复杂度。
参考与出处
- Dong et al., Agentic Reinforced Policy Optimization, arXiv:2507.19849, 2025-07-26.
- 论文 PDF:https://arxiv.org/pdf/2507.19849;代码:https://github.com/dongguanting/ARPO。
- 本文图表均为论文原图裁剪;source map 存放于
/assets/papers/arpo-2507-19849/source_map.json。 - 文中的 Sxxx / Fxxx / Txxx 指向本地 source map 中的段落、图和表。