Context-Folding 论文精读:把长程 Agent 的上下文折起来
解读 Context-Folding 如何用 branch/return 与 FoldGRPO,让长程 Agent 在小活跃上下文里完成深度研究和代码任务。
Paper Reading · arXiv:2510.11967
一句话:这篇论文不是继续把上下文窗口做大,而是教 Agent 主动“折叠”自己的工作记忆。
论文:Scaling Long-Horizon LLM Agent via Context-Folding
作者:Weiwei Sun, Miao Lu, Zhan Ling, Kang Liu, Xuesong Yao, Yiming Yang, Jiecao Chen
机构:ByteDance Seed, Carnegie Mellon University, Stanford University
日期:2025-10-15 · 链接:PDF · Project Page
适合读者:熟悉 ReAct、工具调用 Agent、RLVR / GRPO 或 SWE-Bench 的读者。阅读时长约 18 分钟。
长程 Agent 的瓶颈不是只有窗口长度
ReAct 式 Agent 会把推理、工具调用和 observation 线性塞回同一个上下文;任务越长,模型越难找相关信息,attention 和 KV-cache 成本也越高。(p.1, S002)
branch / return 把子任务变成临时轨迹
Agent 可 branch 出独立工作上下文,做完后 return 一段结果摘要;中间搜索、bash、编辑等 token-heavy 过程被折叠,只把结论留在主线程。(p.3, S005)
FoldGRPO 把“会折叠”训练成能力
论文在 GRPO 上加入动态 folded context 和 token-level process reward,惩罚主线程里未折叠的重操作、越界分支和失败工具调用。(p.5, S008-S009)
32K 活跃上下文,最多 10 个分支
Folding Agent + FoldGRPO 在 BrowseComp-Plus 达到 0.620 Pass@1,在 SWE-Bench Verified 达到 0.580;活跃上下文只有 32K,但总 token 预算可到 32K × 10。(p.7, S011)
我的快速判断
- 这篇论文真正有价值的点:它把“上下文管理”从外部工程策略,变成了 Agent 可学习、可优化的行为。
- 最该关注的风险:return 摘要是信息瓶颈;一旦摘要漏掉关键证据,主线程无法恢复被折叠的细节。
- 最像工程可落地的部分:branch/return API、主线程规划 + 分支执行、KV-cache rollback,都可以直接映射到现有 Agent 框架。
1. 这篇论文到底解决什么问题?
论文的问题设定很直接:LLM Agent 正在被用于 deep research 和 agentic coding 这类长程任务,但经典 ReAct 框架会把完整交互历史 (a1,o1,...,aT,oT) 全部放进下一步生成上下文。工具调用越多,observation 越长,主上下文越像一个不断膨胀的日志文件。(p.1, S002; p.3, S004)
长上下文带来的问题有两层:
- 能力层:模型在极长上下文中检索和使用相关信息会退化;即使信息还在窗口内,也未必能被稳定利用。
- 效率层:attention 的计算成本和 KV-cache 管理开销随上下文增长而变重,长程任务的推理和训练都更贵。
已有两类解法都不彻底。摘要式方法通常在上下文满时触发一次 post-hoc summary,可能突然打断当前工作流;多 Agent 系统把任务分给不同角色,但往往依赖手工流程,难以端到端优化。Context-Folding 的核心假设是:上下文压缩不应该只是外部机制,而应该成为 Agent 主动学会的技能。(p.1, S002; p.11, S016)

2. 方法总览:Context Folding 是一种可学习的工作记忆管理
Context Folding 引入两个特殊动作:
branch(description, prompt):从主线程创建一个临时子轨迹,用独立工作上下文完成局部子任务。return(message):结束分支,把分支中间步骤折叠掉,只把message作为结果写回主线程。
用论文符号说,普通 ReAct 在第 i 步以完整历史为条件生成动作;Context Folding 则用一个上下文管理器 F(τ<i) 先折叠 branch-return 之间的片段,再把折叠后的历史喂给模型。(p.3, S005)
普通 ReAct:
next_action ~ πθ(action | question, full_history)
Context Folding:
next_action ~ πθ(action | question, F(full_history))
F 的效果:
main: ... branch ... many actions/observations ... return(summary) ...
folded: ... branch_created_marker, return(summary) ...论文还给了一个关键工程细节:推理时可以管理 KV-cache。调用 return 时,系统把 KV-cache 回滚到对应 branch 位置;因为分支前的 prefix 与主线程一致,所以折叠在推理上不是简单“重新拼 prompt”,而是有缓存友好的实现路径。(p.4, S006)
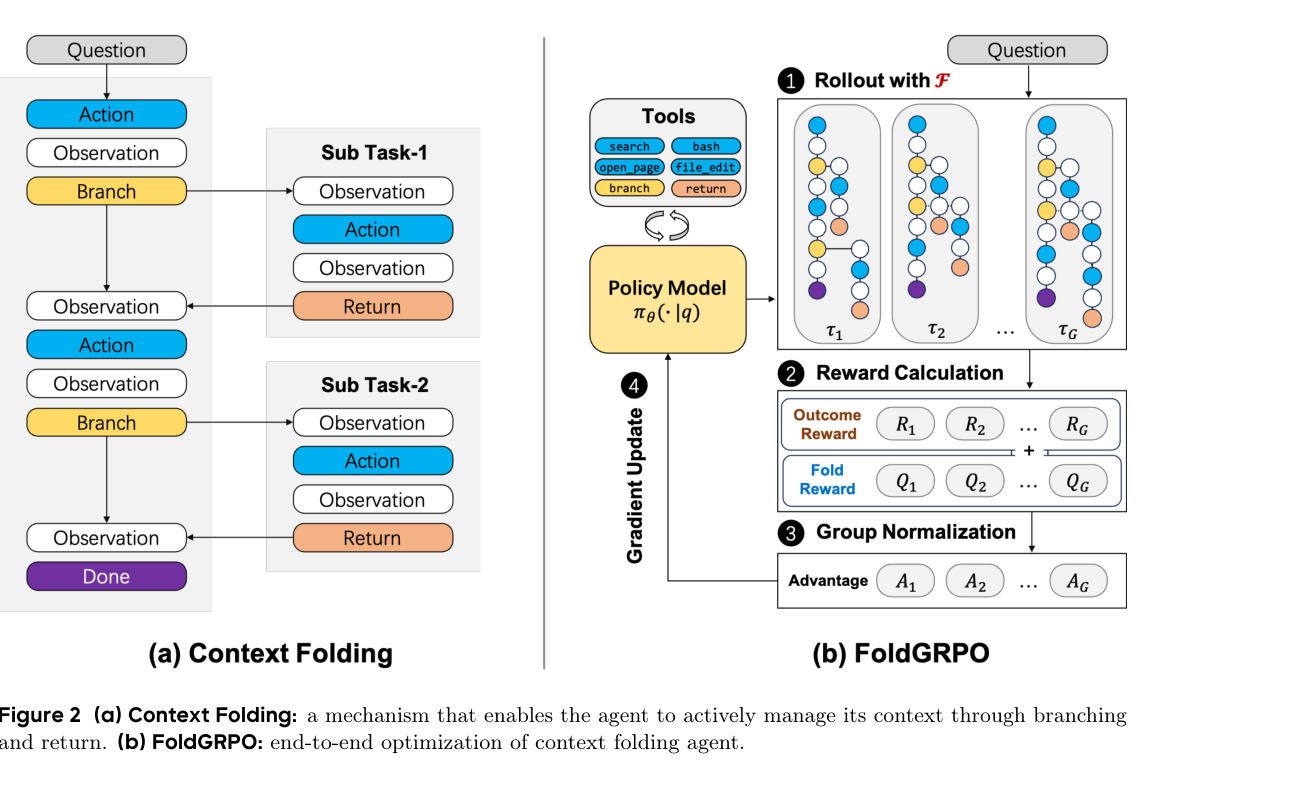
2.1 plan-execution:主线程负责规划,分支负责执行
作者把 Context Folding 实例化成 plan-execution 框架:
- Planning State:主线程做高层推理、任务分解和分支决策;论文明确鼓励主线程避免 token-intensive 工具使用。
- Execution State:分支执行具体子任务,例如搜索网页、读文件、跑测试。为避免嵌套复杂度,执行态中禁用继续创建新分支。
这点很重要:它不是任意递归多 Agent,而是一种强约束的“主线程调度 + 一层分支执行”。这种结构降低了训练和信用分配难度,也让 return 摘要成为清晰的压缩边界。(p.4, S007)
3. FoldGRPO:训练 Agent 学会什么时候折、怎么折
如果只给最终成败奖励,Agent 未必会自然学会良好的折叠行为。作者观察到两个失败模式:第一,Agent 不会战略性规划,把 token-heavy 操作留在主线程,导致上下文预算快速耗尽;第二,Agent 进入分支后不及时 return,或者在分支里继续做越界任务。(p.5, S009)
FoldGRPO 因此在标准 GRPO / RLVR 思路上加入两个设计:
- 动态 folded context:优化每个 LLM token 时,条件上下文不是完整历史,而是经过
F折叠后的历史。 - token-level process reward:除了最终 outcome reward,还给 token 级别的行为奖励/惩罚,直接塑造 branch-return 习惯。
3.1 三类过程奖励
- Unfolded token penalty:当主线程总上下文超过工作窗口 50% 后,对主线程 token 施加
Qi,t = -1,但创建 branch 的回合除外。直觉是:主线程快变胖了,就应该把重操作放进分支。 - Out-of-scope penalty:用 GPT-5-nano 根据 branch prompt 和 return message 判断分支是否做了子任务外的事;若越界,对该分支 token 施加
Qi,t = -0.2。直觉是:分支不是新主线,要聚焦。 - Failure penalty:失败工具调用回合施加
Qi,t = -1。直觉是:折叠不能掩盖无效工具使用。
我认为这三类奖励的组合是论文最关键的训练贡献:它没有只奖励“少 token”,而是同时奖励主线程轻量、分支聚焦、工具有效。这更接近真实 Agent 工程中想要的行为。(p.5, S008-S009)
4. 实验:32K 活跃上下文是否能打过 327K ReAct?
论文评估两类长程任务:
- Deep Research:BrowseComp-Plus,680 个训练样本、150 个评测样本;工具是
search(query, topk)和open_page(url)。 - Agentic SWE:SWE-Bench Verified 作为评测集;训练数据来自 SWE-Gym 和 SWE-Rebench 中难度适中的实例,共 740 个;工具包括
execute_bash、str_replace_editor和think。
基础模型是 Seed-OSS-36B-Instruct。Folding Agent 的单次 LLM 最大上下文是 32,768,允许最多 10 个分支,因此理论最大 token 预算为 327,680;推理使用 greedy decoding。(p.6, S010)
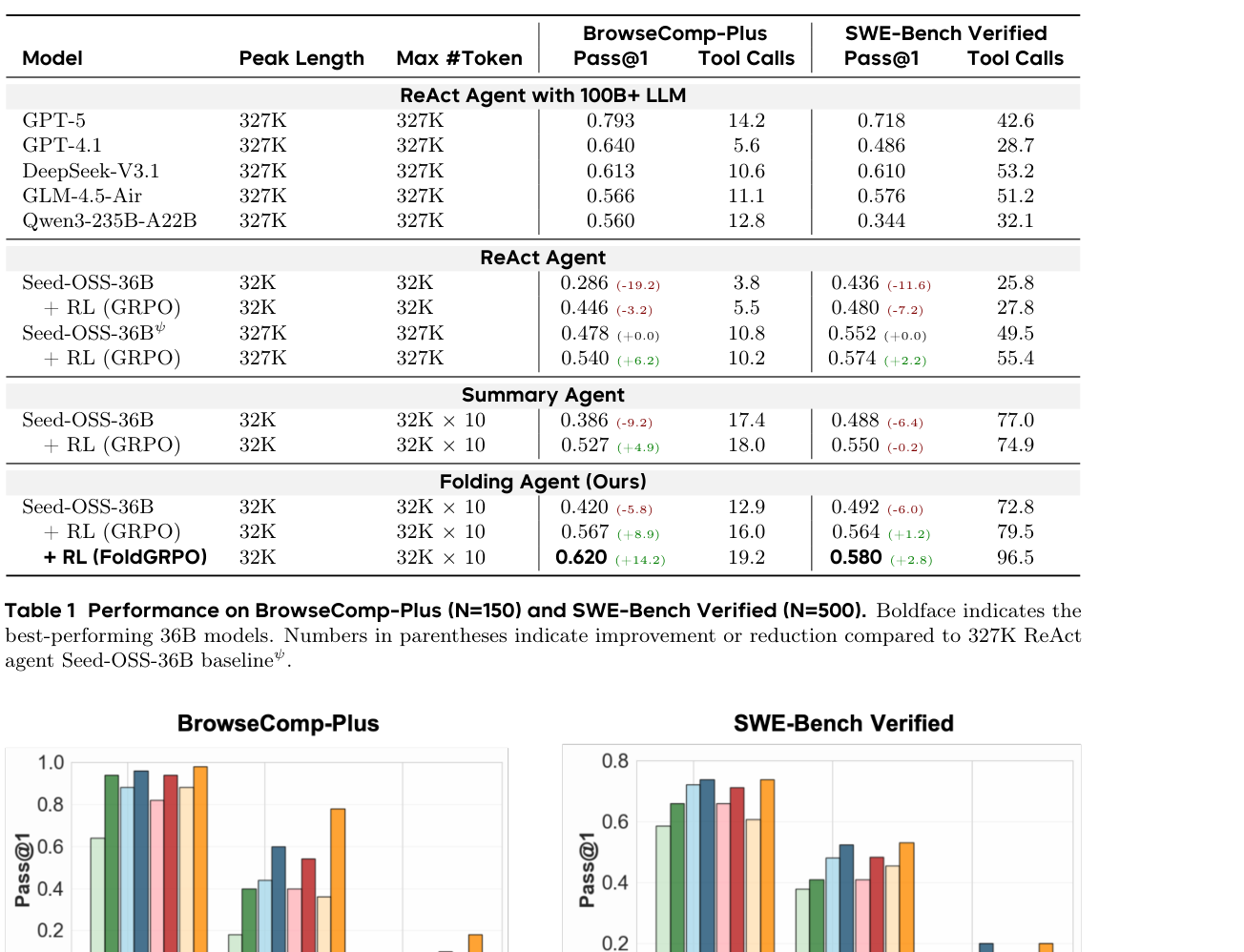
4.1 主结果怎么读?
表 1 中最值得看的是三组可比 baseline:
- 32K ReAct:同样活跃上下文,BrowseComp-Plus 只有 0.286,SWE-Bench Verified 为 0.436。
- 327K ReAct:直接把上下文拉长,BrowseComp-Plus 为 0.478,SWE-Bench Verified 为 0.552。
- Summary Agent:给 32K × 10 的摘要预算,RL 后 BrowseComp-Plus 为 0.527,SWE-Bench Verified 为 0.550。
Folding Agent + FoldGRPO 的结果是 0.620 / 0.580。也就是说,这篇论文的论证重点不是“折叠比所有大模型都强”——GPT-5 在表中依然更强——而是在 36B 级别模型上,学会主动上下文管理能比单纯长上下文或摘要策略更有效。(p.7-p.8, S011-S012)
5. 消融:FoldGRPO 到底改变了什么行为?
论文表 2 的行为统计比主榜单更能说明问题。标准 GRPO 会提高最终表现,但也可能带来坏习惯:轨迹变长、分支不够聚焦、完成率下降。FoldGRPO 通过过程奖励修正这些问题。
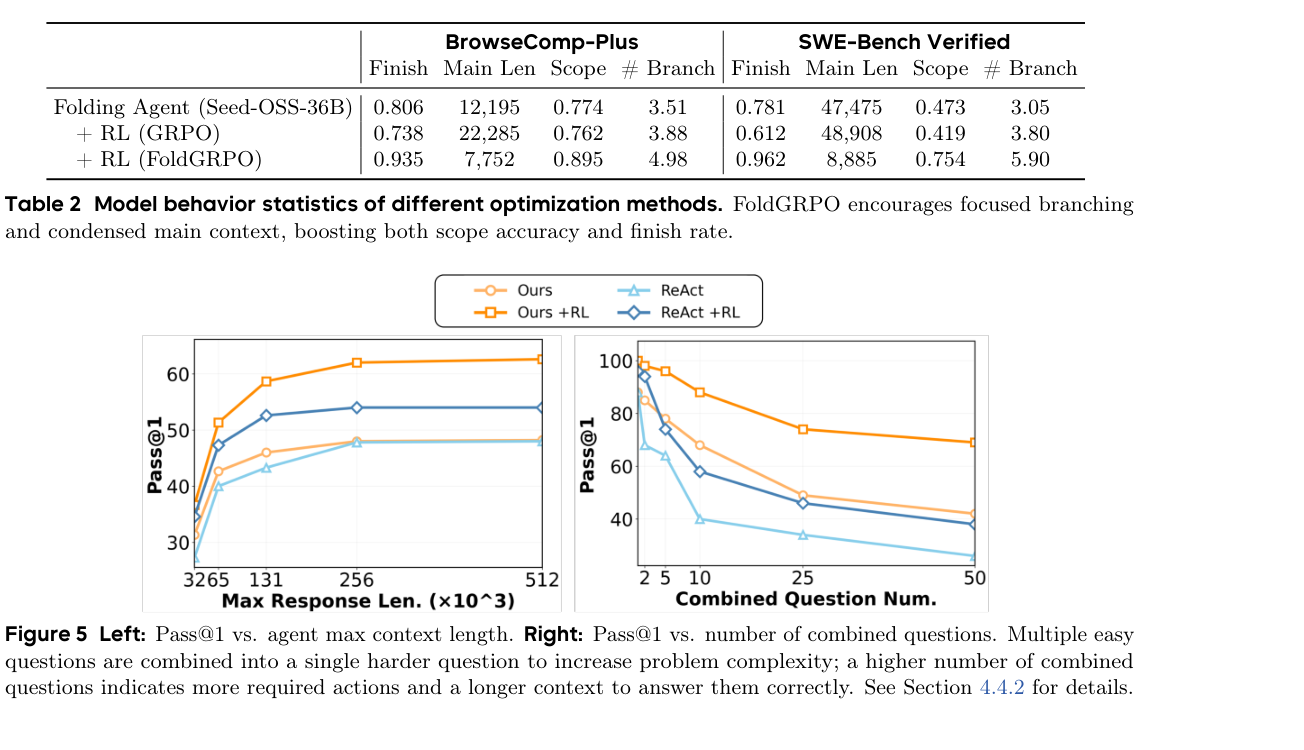
几个数字值得单独记:
- BrowseComp-Plus:FoldGRPO 的主线程长度为 7,752,而普通 GRPO 是 22,285;Finish 从 0.738 提到 0.935。
- SWE-Bench Verified:FoldGRPO 的主线程长度为 8,885,而普通 GRPO 是 48,908;Scope 从 0.419 提到 0.754。
- 论文称其在处理超过 100K 总 token 的同时,将主上下文压到约 8K,达到超过 90% 的上下文压缩。(p.8-p.9, S012)
这说明 FoldGRPO 不是简单让模型“少说话”,而是让模型把 token 花在分支里,再把主线程变成压缩后的决策日志。
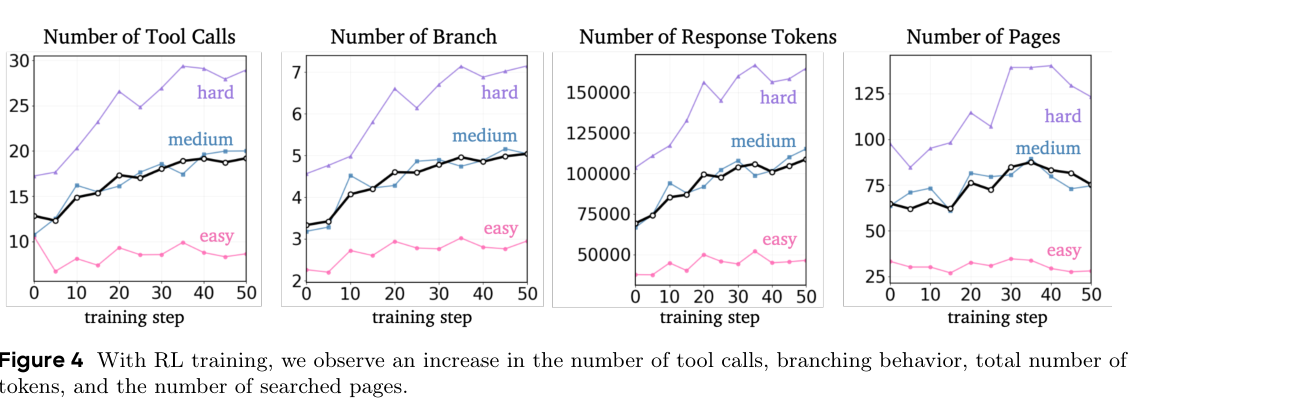
6. 长度泛化与案例:折叠真的留下了足够信息吗?
论文做了两个进一步分析。第一,改变分支数来改变最大 token 预算:Folding 在不同预算下都超过 ReAct,但 320K 之后收益趋于平台,因为多数任务已经完成。第二,把多个简单问题合成一个复合问题;当组合问题数量从 1 增到 50 时,Folding 的相对优势更明显。特别是,模型训练时最多使用 10 个分支,但在 50 个组合问题上会自适应使用平均 32.6 个分支。(p.9, S013)

这个案例也暴露了方法的核心假设:return message 必须保留足够“决策相关”的信息。如果 return 只写“已搜索,没找到”,主线程就失去可审计证据;如果 return 把所有网页片段都塞回去,又失去折叠意义。所以真正难的是学会写有用的分支摘要,而不仅是学会调用 return。
7. 与摘要、多 Agent 的关系
Context Folding 与摘要式记忆、传统多 Agent 都相似,但边界不同:
- 相对摘要式方法:它不是上下文满了才被动总结,而是任务执行过程中主动决定哪些子轨迹应当隔离和折叠。
- 相对多 Agent:分支像临时子 Agent,但没有预定义角色;主线程和分支共享 branch 前的 prefix,因此更适合 KV-cache;分支与主线程交错执行,而非默认并行。
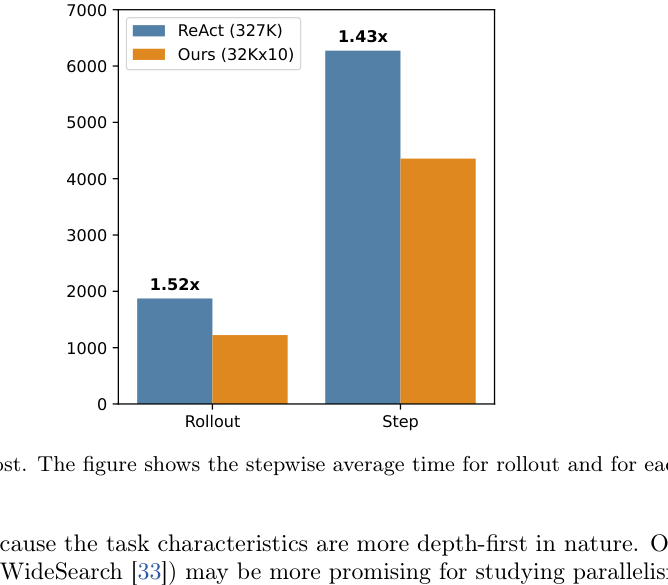
论文还尝试了 parallel branching:在 BrowseComp-Plus 上达到 0.6133 Pass@1,与单分支版本相近;作者推测 BrowseComp-Plus 更偏 depth-first,因此并行未带来更高分数。这个结果提醒我们:折叠机制不等于并行机制,是否并行要看任务结构。(p.5, S006; p.10-p.11, S015)
8. 局限与我会继续追问的问题
return 摘要可验证吗?
论文评估最终成败和 scope,但真实场景还需要检查分支摘要是否忠实于被折叠证据。否则 Agent 可能产生“压缩幻觉”。
谁来决定摘要粒度?
当前 return message 由模型写。对代码任务,可能需要结构化字段:改动文件、复现命令、失败日志、测试结论,而不是自由文本。
过程奖励是否依赖强 judge?
Out-of-scope penalty 使用 GPT-5-nano 判断分支是否越界。若换成更弱或更便宜的 judge,训练信号会怎样变化?
多层折叠如何做信用分配?
作者把多层 Context Folding 列为未来方向。若 fold 还能继续 fold,训练时 reward 如何回传到内层摘要,是一个更难的问题。
9. 工程启发:如果要把它放进 Agent 框架
我会优先实现一个保守版本:
1. 主线程只允许:规划、创建分支、读取 return 摘要、最终决策。
2. 分支允许:搜索 / bash / 文件编辑 / 测试等 token-heavy 操作。
3. return 使用结构化模板:
- subtask
- actions_taken
- key_evidence
- result
- caveats
- next_recommendation
4. 主线程保留 source handles,而不保留完整 observation。
5. 对 return 做自动校验:抽样回放分支证据,检查摘要是否遗漏或歪曲。这样即使没有立即做 FoldGRPO 训练,也可以先把 Context Folding 当作一种 Agent runtime 设计:用 API 和日志结构强迫主线程保持短、分支保持聚焦。训练部分则可作为后续优化。
这篇论文最值得带走的思想是:长程智能体的上下文不是一个越大越好的容器,而是一种需要被策略性管理的工作记忆。
参考与出处
- Sun et al., Scaling Long-Horizon LLM Agent via Context-Folding, arXiv:2510.11967, 2025-10-15.
- 本文图表均为论文原图裁剪;source map 存放于
/assets/papers/arxiv-2510-11967/source_map.json。 - 本读书笔记中的 Sxxx / Fxxx / Txxx 指向本地 source map 中的段落、图和表。