SDPO 论文精读:让强化学习从“结果分数”转向“失败反馈”学习
解读 Reinforcement Learning via Self-Distillation 如何把运行时报错、判题文本和成功样例转成密集信用分配,并在代码、推理与测试时训练中提升样本效率。
Paper Reading · arXiv:2601.20802
一句话:这篇论文的核心不是“再造一个更强教师”,而是让模型在看到失败反馈后,回头重判自己刚才每一步 token 到底哪里错了。
论文:Reinforcement Learning via Self-Distillation
作者:Jonas Hubotter, Frederike Lubeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, Andreas Krause
机构:ETH Zurich, Max Planck Institute for Intelligent Systems, MIT, Stanford
版本日期:2026-01-28 · 链接:arXiv · PDF · Code
适合读者:熟悉 RLHF / RLVR、GRPO / PPO、LLM 代码与推理后训练的读者。阅读时长约 22 分钟。
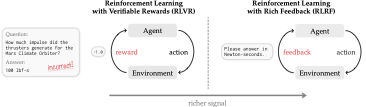
RLVR 只看最终 reward,信用分配太稀疏
标准 RLVR 往往只拿到一次标量结果,比如 pass / fail。这样模型知道“错了”,却不知道“错在第几个 token、哪种推理、哪段代码”。论文把这称为 credit-assignment bottleneck。
让当前模型充当 hindsight self-teacher
同一个模型先作为 student 生成答案,再在看到 rich feedback 后作为 self-teacher 重新评估原答案每个位置的 next-token 分布,并把这种 hindsight 差异蒸馏回 student。
代码任务更快更强,推理任务更短更准
在 LiveCodeBench v6 上,Qwen3-8B 的 SDPO 最终准确率 48.8%,高于 GRPO 的 41.2%,并以约 4 倍更少生成量达到 GRPO 最终水平;在无 rich feedback 的标准 RLVR 任务中,也能超过强 GRPO baseline。
“失败反馈”本身就是一种老师
只要环境能返回足够有信息量的文本反馈,模型就可能通过 hindsight 自蒸馏,把失败案例变成密集监督,而不必依赖外部强教师或单独奖励模型。
我的快速判断
- 最值得记住的贡献:把 rich textual feedback 显式形式化成 Reinforcement Learning with Rich Feedback(RLRF),并给出一个可以直接嵌进现有 RLVR pipeline 的算法。
- 最强的直觉:模型不是只在“再次采样时修正自己”,而是在“重读自己失败答案时”给每个 token 一个 hindsight 评价。
- 最重要的边界:这个方法吃模型的 in-context 反思能力,也吃环境反馈质量;弱模型或低信息反馈时,收益会明显变差,甚至不如 GRPO。
1. 这篇论文到底要解决什么问题?
当前很多大模型后训练工作发生在 RLVR(reinforcement learning with verifiable rewards)场景:给问题 x,采样回答 y,环境返回一个标量 reward r。这在代码、数学、工具调用里很常见,比如单元测试是否通过、答案是否正确、工具调用是否匹配规范。
问题是:标量 reward 信息量太低。如果一次代码生成最后得到 0 分,模型知道“这次不对”,但它并不知道:
- 是思路错了,还是只在某个边界条件崩了;
- 是前面几十个 token 都有问题,还是最后一个返回值错了;
- 是运行时错误、内存错误、索引越界,还是 judge 说逻辑不成立。
这就是论文说的 credit assignment bottleneck:学习信号只告诉你 outcome,却不告诉你 error surface。GRPO 这类方法虽然能从组内相对回报估计 advantage,但当一组 rollout 都失败时,优势信号会塌成 0,学习停滞。
2. 论文的核心想法:同一个模型,先当学生,再当 hindsight 老师
SDPO(Self-Distillation Policy Optimization)最漂亮的一点,是它没有引入外部强教师。作者直接把当前策略本身拆成两个角色:
- student:在没有额外反馈时,先生成原始答案;
- self-teacher:在看到 rich feedback 后,重新评估这份原始答案,判断每个位置本来更应该生成什么。
这不是再次采样一条新答案,而是对同一条已生成轨迹重新算 log-prob。区别只在于 teacher 的上下文里多了反馈,因此 teacher 对原 token 序列会出现“赞成”或“反对”的局部概率变化。SDPO 就把这种变化蒸馏回 student。
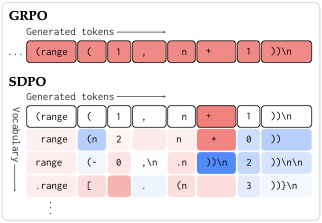
3. 方法怎么写成公式?它和 GRPO 本质差在哪?
论文把 student 和 self-teacher 的 token 分布差异,写成一个逐 token 的蒸馏损失:
L_SDPO(theta) = sum_t KL(
pi_theta(. | x, y_{<t})
||
stopgrad(pi_theta(. | x, f, y_{<t}))
)其中 x 是原问题,y 是 student 已经生成的回答,f 是 rich feedback。直观上看:
- 如果 teacher 在看到反馈后,觉得当前位置原本那个 token 很合理,那么 student 几乎不改;
- 如果 teacher 强烈认为某个位置应该换一种延续,student 就会在那个位置收到强烈更新信号。
所以它和 GRPO 的本质差异,不只是 reward 来源不同,而是advantage 粒度不同:
- GRPO:一次 rollout 里的所有 token 基本共享同一个 sequence-level / group-level 信号;
- SDPO:每个位置、甚至每个候选 token,都可以有不同强度和方向的 advantage。
论文把这一点写得非常明确:GRPO 的优势在 token 维度上是常数,而 SDPO 的优势是 logit-level 的,来自 teacher 与 student 的对数概率比值。
可以把 SDPO 理解成什么?
- 不是“用反馈重写一份正确答案,再做 SFT”。
- 而是“让模型在 hindsight 视角下,对自己原答案做逐位置打分,再把这种打分转回 policy gradient / distillation 更新”。
- 这让失败样本也有学习价值,而且价值不止一个 0/1 分数。
4. 什么叫 RLRF?为什么这比 RLVR 更一般?
论文提出了一个更一般的训练设定:Reinforcement Learning with Rich Feedback(RLRF)。在这个设定里,环境返回的不只是 reward,还可以是任意 tokenized state signal,例如:
- 代码环境中的 runtime error、wrong answer、memory error;
- LLM judge 给出的失败原因;
- 工具调用环境的观察结果;
- 甚至同一 batch 中别的成功样例。
作者的一个重要观点是:RLVR 其实是 RLRF 的一个特例。很多任务本来就有丰富反馈,只是我们训练时把它压扁成了标量,白白丢掉了信息。
这也解释了为什么 SDPO 的适用面不只限于“有详细判题日志”的环境。论文甚至展示:在没有 rich environment feedback 的标准 RLVR 环境里,也可以把同一 batch 中的成功 rollout 当作 failed attempt 的“反馈”,仍然得到明显收益。
5. 论文做了三类实验,分别证明什么?
这篇论文的实验结构很清楚,基本是在回答三个问题:
- 没有 rich feedback 时,SDPO 还有用吗?
- 有 rich feedback 时,它能否显著超过 RLVR baseline?
- 在 test time,它能不能加速“第一次找到解”的过程?
下面分别看。
6. 实验一:没有 rich feedback,SDPO 仍然能赢
作者先在标准 RLVR 任务上测试 SDPO:科学问答(Chemistry、Physics、Biology、Materials)和 Tool Use。这里环境本身并不会返回长文本反馈,所以作者做了一个很巧的替代:把同一批次里已经成功的 sample,当成 failed sample 的反馈上下文。
结果上,论文在 introduction 里给了一个总括结论:在这类“无 rich feedback”的任务上,SDPO 相比强 GRPO baseline 的 aggregate final accuracy 是 70.2% vs. 66.6%,而且生成长度能缩短到最高约 11 倍。这意味着 SDPO 学到的不只是“更准”,而是“更高效地推理”。
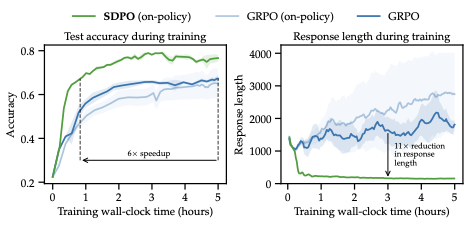
这里我觉得最有意思的结论不是分数,而是生成行为变化。作者观察到:GRPO 往往学出更长、更绕、带有 “Hmm / Wait / going in circles” 这类表面思考痕迹的输出;而 SDPO 倾向于生成更短、更直接的推理。论文把这解释为:SDPO 的密集信用分配让模型能精细地修正 reasoning path,而不只是通过增加长度来碰运气。
7. 实验二:有 rich feedback 时,代码任务提升最明显
第二部分实验是在 LiveCodeBench v6 上做的。这里环境天然会返回 rich feedback,例如运行时错误、失败测试信息等,非常适合 SDPO 发挥。
主结果非常直观:Qwen3-8B 上,SDPO 的最终准确率达到 48.8%,而 GRPO 是 41.2%;同时,SDPO 以大约 4 倍更少的 generations 达到 GRPO 的最终水平。作者还拿公开 leaderboard 上的 Claude Sonnet 4、Claude Opus 4 做了对照,说明这个训练后的专门模型在该子集上已经超过这些强指令模型。
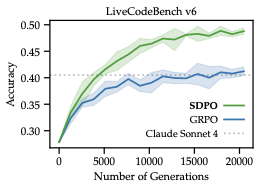
更进一步,论文还做了按模型规模的对比,发现 SDPO 的收益会随着模型变强而增大。作者的解释是:self-teacher 的 retrospection 能力,本质上依赖模型本身的 in-context learning 能力。模型越强,越能在看到反馈后正确判断“刚才到底哪里错”。
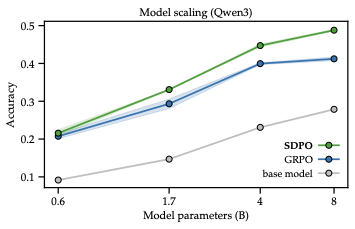
8. rich feedback 和 dense credit assignment,哪个更重要?
作者没有停在“结果更好”,而是继续拆因果:SDPO 强,到底是因为它用了 richer feedback,还是因为它做了 denser credit assignment?
为此,论文比较了三种版本:
- logit-level SDPO:每个位置看 top-K 候选 token;
- token-level SDPO:每个位置只看最可能 token;
- sequence-level SDPO:把 token 级优势再平均回一个序列级标量。
结论很干净:两者都重要,而且互补。即使 sequence-level SDPO,只要用了 rich feedback,也比 GRPO 强;但 logit-level SDPO 最强,说明更密集的信用分配确实提供了额外收益。
这意味着这篇论文并不是“单纯换了个 teacher 模板”,而是真正在算法层面提出了一个更细粒度的学习信号结构。
9. SDPO 的一个关键洞察:teacher 也会变强,而且学生能超过初始 teacher
直觉上你可能会担心:既然 teacher 也是当前模型,那会不会陷入“自己教自己,天花板就是初始能力”?论文专门验证了这个问题。
答案是:不会。因为 teacher 看到的是带反馈的上下文,它本来就比 student 拥有更多信息;而随着训练进行,这个 feedback-conditioned teacher 自己也会变强。论文甚至显示:后期 student 的性能可以超过最初 self-teacher 的 generative accuracy。这说明 SDPO 不是原地自举,而是真正通过 on-policy self-distillation 持续抬升能力。
作者为防止 teacher 漂移过快,还加入了 teacher regularization,例如 EMA teacher 或 trust-region 式的 regularized teacher。这类技巧的目的,是避免“teacher 与 student 一起发散”。
10. Test-Time Self-Distillation:把训练思想搬到单题求解
论文最后一部分我觉得很有启发性:作者把 SDPO 用在单个测试问题上,也就是 Test-Time Self-Distillation(TTT)。目标不是做长期训练,而是在一道非常难的 binary-reward 题目上,更快找到第一组可行解。
他们挑了 LiveCodeBench 中一批特别难的问题,其中很多题 base model 的 pass@64 低于 0.03。结果显示,TTT 版 SDPO 可以用大约 3 倍更少尝试 达到 best-of-k 或 multi-turn conversation 相近的 discovery probability。
这件事很值得注意:传统 RLVR 方法往往要先“撞到一次成功”才有正学习信号;但 SDPO 因为能直接从 rich feedback 中学,所以在一次都没成功之前,仍然可能通过 hindsight signal 持续推进搜索。

11. 我怎么理解这篇论文的真正贡献?
如果只看表面,这篇工作像是“用 feedback 做 self-distillation”;但我认为它真正的贡献有三层:
- 问题层:把 RLVR 的局限明确表述为“标量 reward 信息瓶颈”,并提出 RLRF 这个更一般的视角。
- 算法层:提出一种无需外部强教师的 on-policy self-distillation 方案,把 hindsight feedback 直接转成 token / logit 级学习信号。
- 经验层:证明 rich feedback 与 dense credit assignment 是互补的;同时证明这种方法并不局限于离线蒸馏,而能嵌入真实 RL pipeline,甚至扩展到 test-time specialization。
这三点合在一起,才让它不仅是“另一个 RL trick”,而更像是对 LLM post-training 信号形态的一次重构。
我对这篇论文最核心的总结是:很多后训练环境不是“没有老师”,而是我们之前没有把环境本身的失败反馈当作老师。
12. 这篇论文有哪些局限?
依赖底模的 hindsight 能力
论文明确显示,SDPO 的收益随模型规模增强。弱模型在看到反馈后,未必真能定位错误,导致 self-teacher 信号不可靠。
依赖环境反馈质量
如果环境只返回低信息量反馈、误导性反馈,或者文本很噪,teacher 的 hindsight 判断就会偏。作者在结论里也直接承认这一点。
额外计算并非零成本
虽然不需要额外采样 teacher response,但仍要额外计算 teacher log-probs。论文认为这比顺序生成便宜很多,但在大规模训练里仍是实打实的算力开销。
目前最强验证集中在可验证任务
代码、工具调用、理科推理都具备相对明确反馈。开放式生成、连续奖励任务、含噪人类偏好场景能否同样受益,论文还没有充分证明。
13. 如果我要把 SDPO 用到自己的系统里,最先落地什么?
如果你正在做代码 agent、browser agent、tool-use agent 或 reasoning post-training,我会优先照着论文抽出下面这套最小实现:
1. 保留每次 rollout 的完整轨迹
- prompt
- sampled response
- per-step tool/action trace
- environment textual feedback
- scalar reward / pass-fail
2. 构造 self-teacher 上下文
- 原问题 x
- 失败后的 rich feedback f
- 可选:同 batch 的成功样例
- 原始响应 y(用于重算 log-prob)
3. 不生成 teacher answer,只重算 teacher 对 y 的 next-token 分布
4. 用 token / top-K logit 级 divergence 更新 student
5. 单独监控
- final pass rate
- response length
- self-teacher generative accuracy
- 失败类型分布
- rich feedback 的信息量如果你不想一开始就完整复现论文,那么也可以先做一个弱版本:只在失败样本上收集 rich feedback,然后把 feedback-conditioned teacher 用作辅助 loss。哪怕先不完全替代 GRPO,也足以测试“环境反馈是否真有额外训练价值”。
14. 深度 Q&A
Q1:SDPO 和“失败后再让模型改一次答案”有什么本质区别?
区别在于训练信号的形式。简单 retry / reflexion 主要利用反馈来生成一条新答案;SDPO 则利用反馈来回看原答案,并把 teacher-student 在每个 token 位置上的分布差异转成学习信号。它训练的是“哪里错、怎么局部修”,而不是只收集一条新的成功轨迹。
Q2:为什么它不需要外部强教师?
因为 rich feedback 本身提供了额外上下文。student 看不到反馈时可能做错;同一个模型在看到反馈后,往往已经足以 hindsight 地识别错误位置。论文押注的就是这种 in-context retrospection 能力。
Q3:没有 rich feedback 的任务为什么也能提升?
作者把“同 batch 的成功样例”当成 failed sample 的替代反馈。这样 teacher 还是能比较当前失败答案与一个可行方向之间的差异,从而给出更细的 credit assignment。
Q4:它是不是本质上还是 policy gradient?
是。论文明确说明 SDPO 可以写成 policy gradient 形式,只不过 advantage 不再来自 sequence-level reward,而是来自 feedback-conditioned self-teacher 对 next-token 分布的评估。
Q5:最容易失败在哪里?
两个地方:一是 teacher 自己 hindsight 能力不够,给不出可靠分布修正;二是环境反馈没有足够语义信息,无法定位错误原因。论文的 scaling study 和结论部分都在提醒这两个边界。
Q6:为什么作者强调 response length 变短?
因为这说明 SDPO 改善的可能不是“多想一会儿”,而是“更会想”。如果一个方法提高准确率的同时还能显著缩短输出,就意味着它可能真的修正了推理结构,而不只是通过长链条堆砌更多采样机会。
Q7:Test-time self-distillation 的意义是什么?
它说明这种方法不只是训练期技巧,而是一个更一般的“利用失败反馈进行在线局部适配”的框架。对难题搜索来说,这几乎是在把 RL 思想做成题目级 optimizer。
Q8:这篇论文对 agent 训练有什么启发?
如果 agent 环境能返回观察、错误提示、网页状态、工具异常等文本,那么就完全可以把这些内容接进 hindsight self-teacher,而不是只在 episode 结束时记一个 0/1 reward。对于真正长轨迹 agent,这可能比继续堆更复杂的 scalar reward engineering 更有前景。
15. 最后总结
我会把这篇论文总结成一句更工程化的话:
不要只把环境当成打分器,要把环境当成批改老师。
在 LLM 后训练里,我们过去太习惯把 rich environment state 压成一个标量结果;SDPO 说明,一旦把失败反馈重新接回 token 级学习过程,模型就能从“知道错了”升级到“知道哪里错、该往哪里改”。这正是 credit assignment 真正需要的东西。
参考与出处
- H botter et al., Reinforcement Learning via Self-Distillation, arXiv:2601.20802, version date 2026-01-28.
- 代码仓库:https://github.com/lasgroup/SDPO。
- 本文图均基于论文源码中的 PDF 图表导出,资源位于
/assets/papers/rl-via-self-distillation-2601-20802/。 - 关键结论依据论文 abstract、introduction、method、results、appendix 中公开数值与图表撰写。