读懂 SDFT:Self-Distillation 如何让模型持续学习而不遗忘
精读 Self-Distillation Enables Continual Learning,拆解 SDFT 如何把示范学习改写成近似 on-policy 的自蒸馏,并分析它为何比 SFT 更能抗遗忘。
Paper Reading · arXiv 2601.19897
一句话:这篇论文最重要的贡献,不是又发明了一种蒸馏,而是把“从示范学习”改写成了“在自己当前策略上学习”。
对持续学习来说,真正致命的往往不是“学新任务”,而是模型被硬拉到专家分布后, 逐步偏离自己原本稳定的能力边界。SDFT 试图解决的正是这个问题。
论文信息
标题:Self-Distillation Enables Continual Learning
作者:Idan Shenfeld, Mehul Damani, Jonas Hubotter, Pulkit Agrawal
时间:2026-01-27
核心判断:如果你关心模型上线后的持续增量训练,而不是一次性的 task adaptation,这篇论文值得认真看。
问题
SFT 从专家答案学习,本质是 off-policy;顺序学多个任务时,容易出现灾难性遗忘。
方法
同一个模型扮演 student 和 teacher:student 只看问题,teacher 额外看 demonstration,再在 student 自己生成的轨迹上做蒸馏。
结果
新任务更强、旧能力掉得更少;在顺序学习多个技能时,SDFT 明显比 SFT 更接近真正的 continual learning。
边界
它依赖模型已有的 in-context learning 能力,更像是“大模型时代的持续学习方法”,而不是小模型通用训练 trick。
TL;DR
这篇论文的核心想法可以写成一句更技术的话:SDFT 用 demonstration-conditioned 同模型 teacher, 在 student 当前策略诱导的轨迹上最小化 reverse KL,从而把 demonstration learning 变成一种近似 on-policy 的自蒸馏更新。
这带来两个结果:一是学新任务时,测试分布和训练分布更一致;二是 teacher 仍然锚定在 base model 附近,所以不会像标准 SFT 一样大幅冲刷原有能力。

1. 这篇论文到底在解决什么问题?
今天的大模型虽然能力很强,但大多数还是“静态”的:发布之后,它们可以通过 prompt、RAG 或 agent 机制临时适应, 却很难像人一样把新技能、新知识稳定写回参数里,而且不伤害旧能力。
这就是 continual learning 的核心难题:模型能不能不断变强,而不是每次适配一个新任务,就把之前学会的东西忘掉?
在现实里,我们最容易拿到的是 demonstration 数据,而不是 reward。于是最常见的做法就是 SFT:拿示范答案,直接监督模型输出。 但作者指出,SFT 虽然方便,却有一个结构性缺陷:它是 off-policy 的,训练时模型只在专家数据分布上被约束,而不是在自己真实会走到的状态上学习。
2. 为什么传统 SFT 不够?
SFT 的问题不是“学不会”,而是学的方式不对。模型在训练中看到的是专家轨迹,但推理时真正执行的是自己的轨迹; 一旦它偏离示范路径,误差就会累积,这正是 imitation learning 里经典的 distribution mismatch。
对单次微调,这个问题有时还不算致命;但对持续学习尤其糟糕。因为每次你都在用一个新的 expert distribution 去重新塑形模型, 旧能力就很容易被覆盖。论文在三个 skill learning 任务上都观察到了这一点:SFT 能把新任务抬起来,但 prior capabilities 会明显下滑。
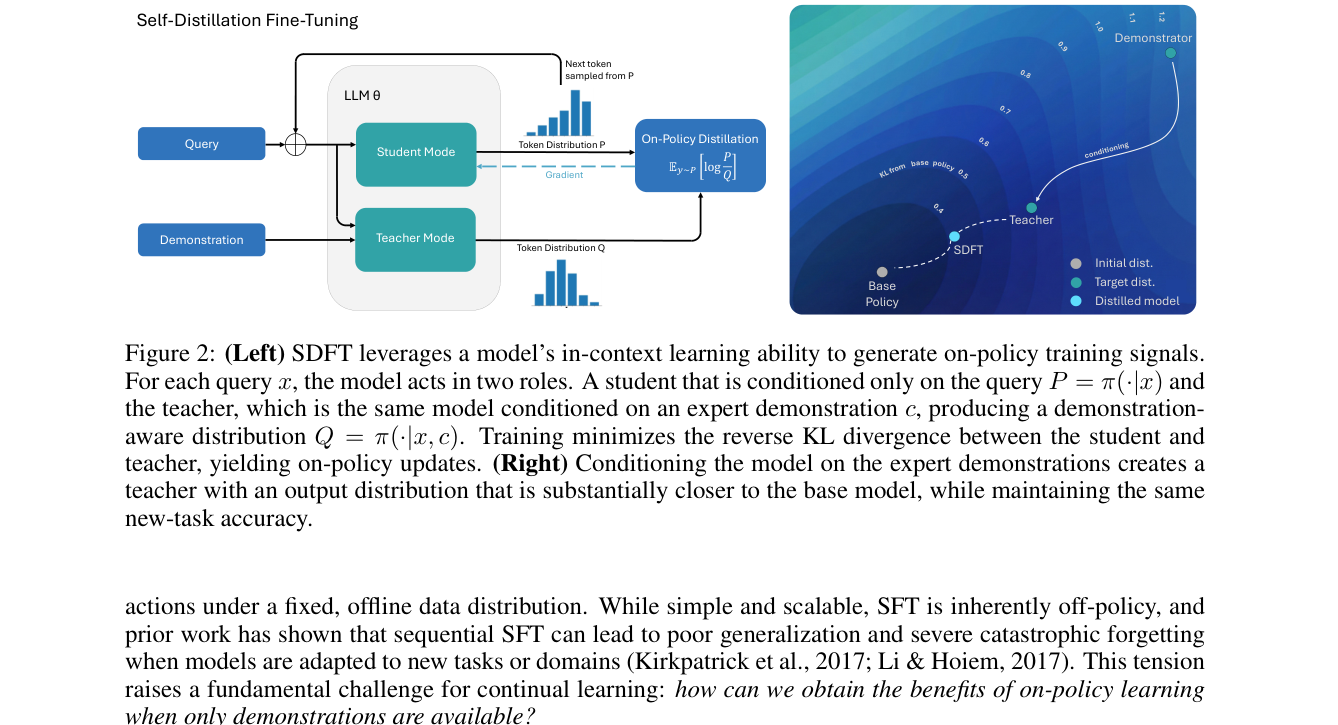
3. SDFT 怎么做?一句话版本
给定问题 x 和一个示范 c:
- student policy:只看
x,记作πθ(.|x) - teacher policy:看
x + c,记作π(.|x,c) - 先从 student 当前策略采样回答
y ~ πθ(.|x) - 再让 student 去匹配 teacher 在这条轨迹上的 token 分布
作者优化的是 reverse KL:DKL(πθ(.|x) || π(.|x,c))。因为期望是对 student 当前分布取的,
所以这个目标天然带有 on-policy 味道。
4. 为什么这比“直接模仿 demonstration”更合理?
关键区别在于:SDFT 不要求 student 去复读某个固定示范,而是让 demonstration 作为一种“上下文提示”, 激活 teacher 对任务意图的理解。换句话说,demonstration 在这里不是硬标签,而是一种把模型推向“更优下一步策略”的条件信息。
这会带来两个好处:
- teacher 输出更贴近当前模型能力边界,不会离 base model 太远;
- 训练发生在 student 自己会访问到的状态上,而不是静态专家数据上。
对 continual learning 来说,这两个性质都很关键:前者帮助保留旧能力,后者帮助提升泛化。
5. 这篇论文最漂亮的地方:把它解释成 implicit IRL
作者不满足于“这是个蒸馏技巧”,而是进一步把 SDFT 放进 trust-region regularized RL 的框架里看。核心假设是:
demonstration-conditioned policy π(.|x,c) 可以近似视作未知最优策略 π*_{k+1}。
一旦接受这个假设,就能推出一个隐式 reward:
r(y,x,c) = log π(y|x,c) - log πk(y|x)
这个 reward 的含义很直观:如果某个 token 在“看过示范后的模型”里更可能,在当前 student 里更不可能, 那它就应该得到正向学习信号。这样,demonstration learning 被重写成了一种无需显式 reward engineering 的 on-policy RL 近似。
SDFT 最有启发性的点,不是“蒸馏”本身,而是它把 demonstration 从“标签”变成了“隐式奖励的载体”。
6. 这个方法的前提:ICL 假设必须基本成立
论文很坦诚地承认,整个方法依赖一个重要假设:模型在看过 demonstration 后,确实能表现得更像一个局部最优策略。
这件事要成立,至少需要两个条件:
- Optimality:teacher 在任务上要明显比 student 更好;
- Minimal deviation:teacher 虽然更好,但不能离 base policy 太远,否则就失去 on-policy 的好处。
这也是为什么作者反复强调模型的 in-context learning 能力。SDFT 不是一个对所有模型都稳定有效的公式, 而是一个建立在“大模型已经具备相当强 ICL 能力”之上的 post-training 方案。
7. 实验怎么设计?
作者把评测分成两大类:
7.1 Skill Learning
目标是:学一个新技能,同时别把旧能力忘掉。任务包括:
- Science Q&A
- Tool Use
- Medical
旧能力则通过 HellaSwag、TruthfulQA、MMLU、IFEval、Winogrande、HumanEval 等 benchmark 汇总评估。
7.2 Knowledge Acquisition
目标是:把 2025 年发生、超出预训练 cutoff 的自然灾害知识注入模型内部参数。这里很有价值, 因为它测试的不是“答题模板有没有学会”,而是模型是否真的把新事实吸收到 memory 里。
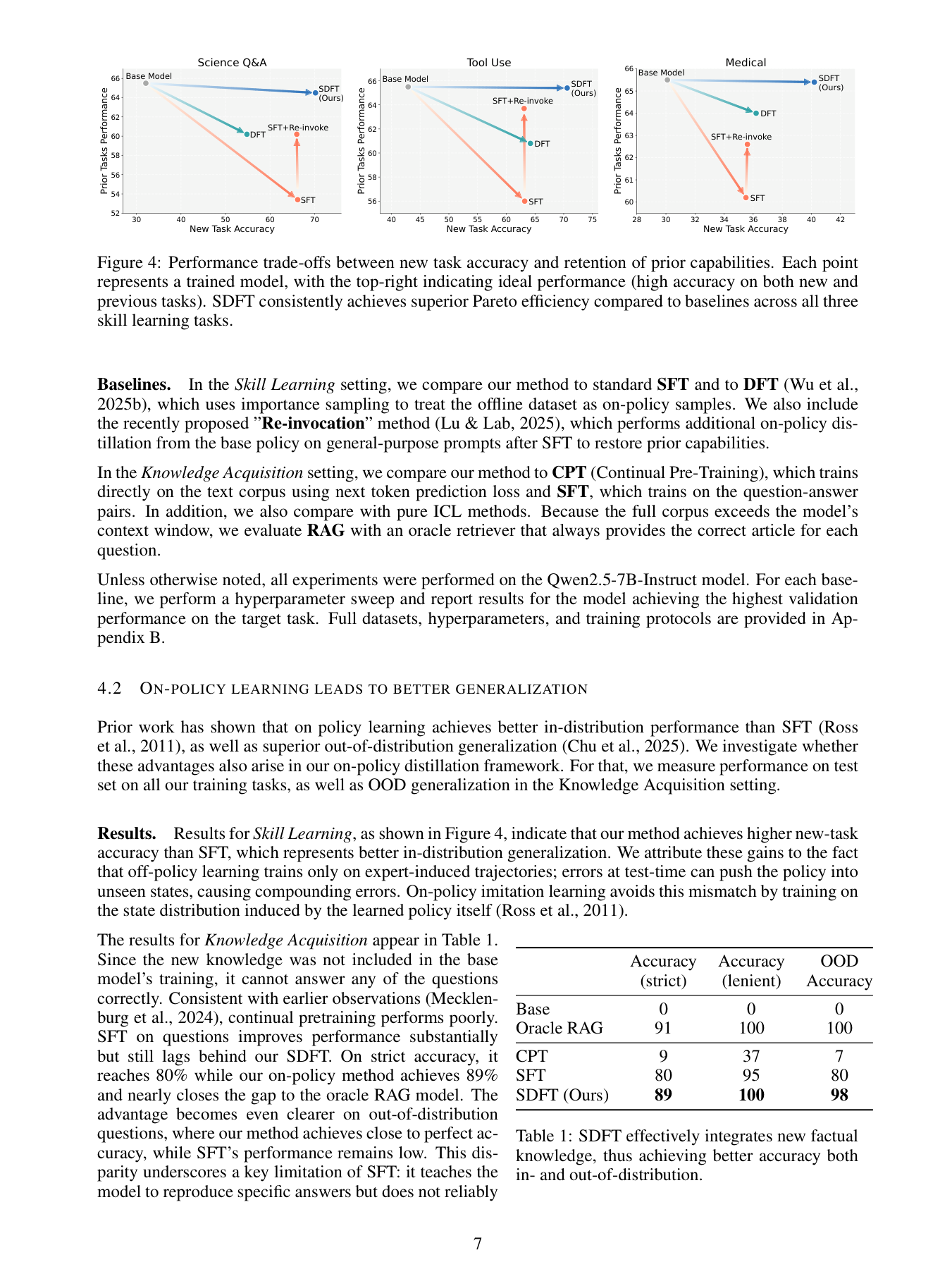
8. 结果里最重要的三件事
8.1 新任务更强,而且旧能力掉得更少
Figure 4 的关键信息很清楚:SDFT 在三个 skill learning 任务上都更接近右上角,也就是更好的 Pareto frontier。 它不是只靠保守更新减少 forgetting,而是在新任务 accuracy 上也普遍优于 SFT。
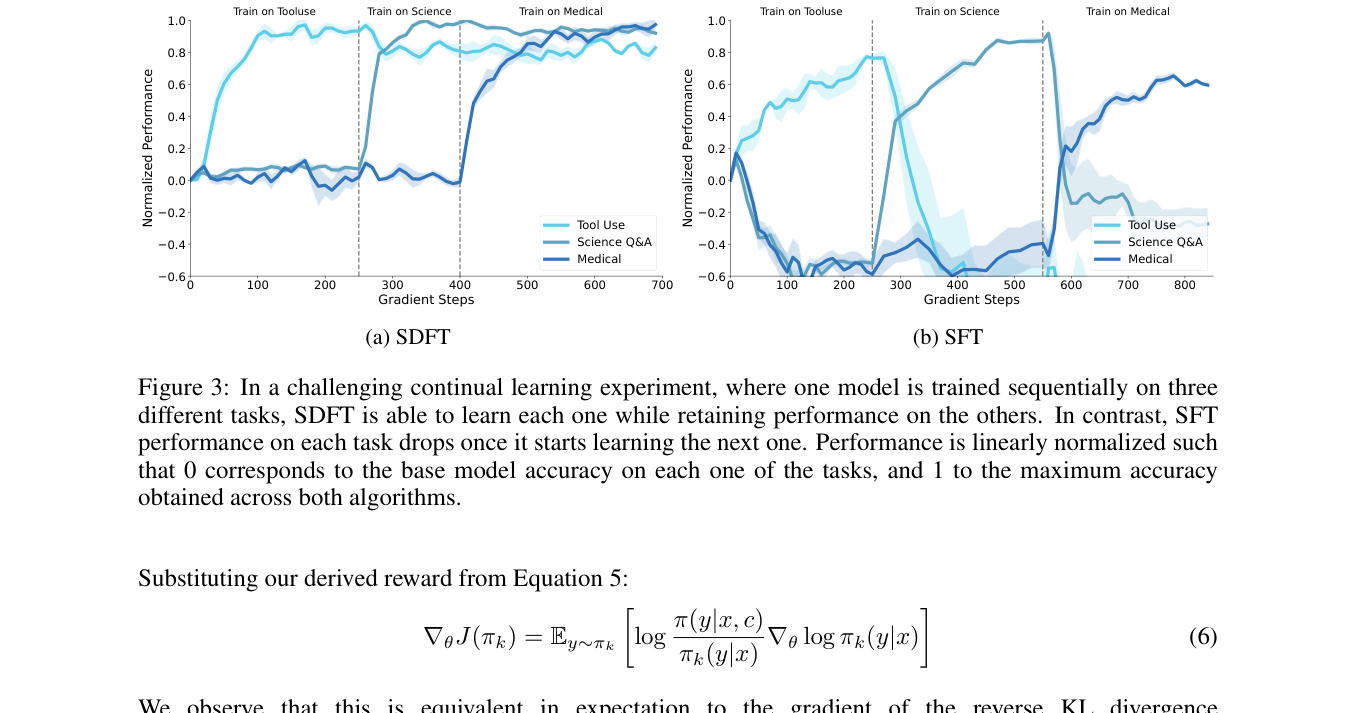
8.2 它真的支持顺序学习多个任务
论文做了更难的 sequential learning:一个模型依次学习 Tool Use、Science Q&A、Medical。结果是, SDFT 基本能做到每学一个新任务,旧任务表现仍然维持;SFT 则会在切换任务后迅速回落。
8.3 对知识注入和 OOD 问法尤其强
在 Knowledge Acquisition 设置中,SFT 已经不算差:strict accuracy 做到 80。但 SDFT 进一步提升到 89, 更夸张的是 OOD accuracy 从 80 提升到 98,几乎追平 oracle RAG。作者据此 argue:SDFT 学到的不是“题型模板”, 而更像是把新知识整合进了模型内部表征。
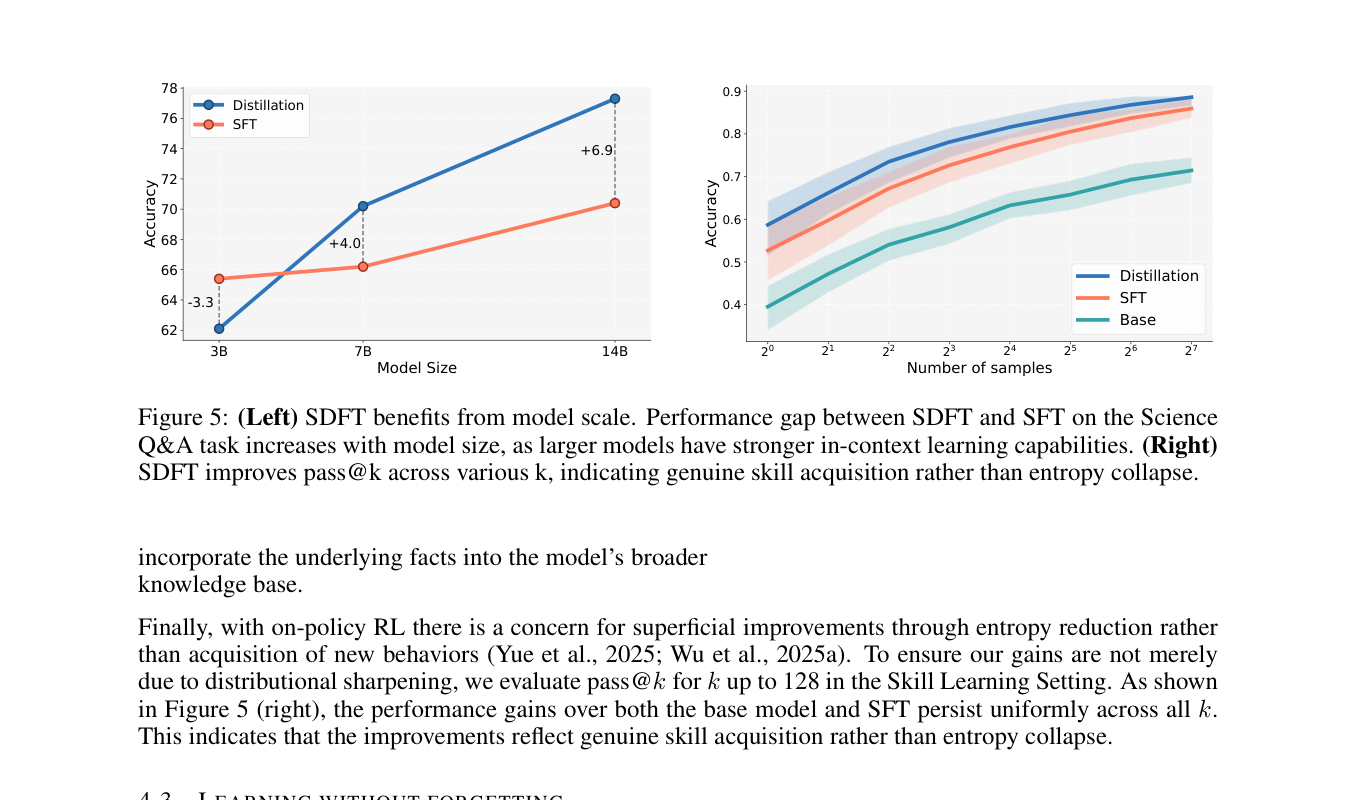
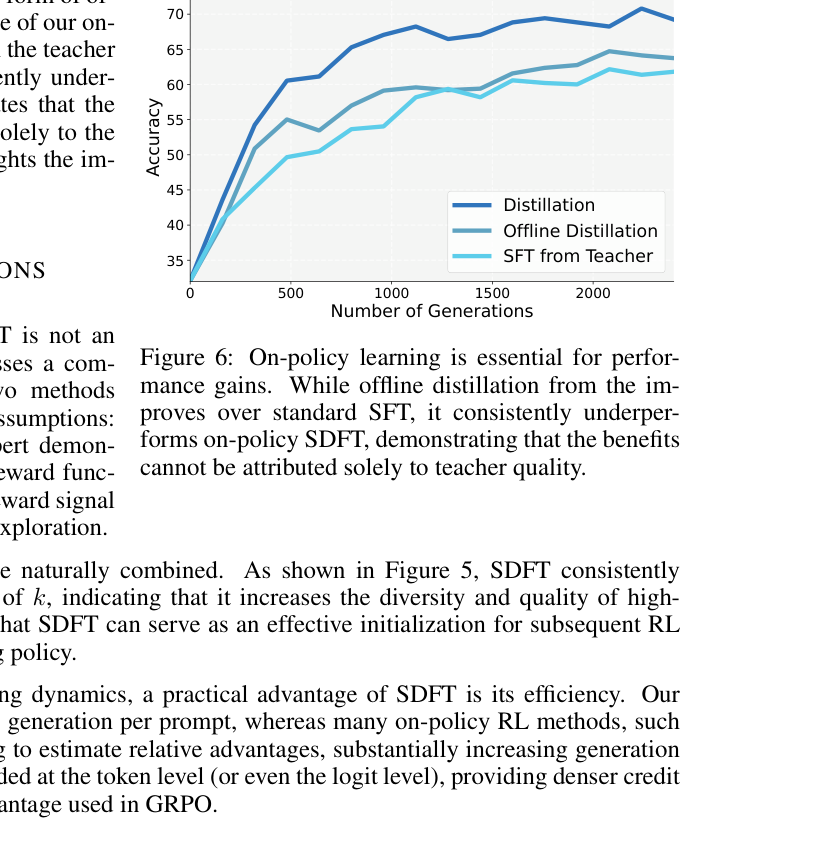
pass@k 上都持续存在,更像真正的 skill acquisition。(出处:论文 Figure 5)9. 一个很强的 practical insight:reasoning model 不要拿 answer-only 数据直接 SFT
论文里我最喜欢的实验之一,是作者拿一个 reasoning model(Olmo-3-7B-Think)在只有 final answer、没有 chain-of-thought 的医疗数据上训练。
结果非常有启发:标准 SFT 不仅准确率下降,还显著缩短输出长度,说明原有 reasoning behavior 被压扁了; 而 SDFT 反而把准确率从 31.2 提高到 43.7,同时保留了更长的推理轨迹。
这意味着,如果你的 base model 已经会推理,外部 supervision 却只有短答案,直接 SFT 可能会把它训“傻”; 而 demonstration-conditioned teacher 可以在没有显式 reasoning trace 的情况下,继续提供 reasoning-consistent 的学习信号。
10. 我对这篇论文的判断
我认为这篇论文最重要的贡献,不是提出一个会替代 SFT 的万能训练算法,而是提供了一个更适合持续后训练时代的思路: 当 reward 很难设计、demonstration 却很丰富时,我们不必在 “SFT” 和 “RL” 之间二选一, 而可以用 self-distillation 的方式,把 demonstration 转换成一种近似 on-policy 的学习信号。
它特别适合这几类问题:
- 模型上线后需要不断注入新知识;
- agent 要逐步积累新技能,而不是每次重新训练;
- 你手里只有 demonstrations,没有明确 reward;
- 你担心 answer-only SFT 会破坏 reasoning model 的内部推理风格。
局限与边界
- 依赖 ICL:小模型效果可能不稳定,论文里 3B 就明显不如 7B / 14B。
- 更适合保守改进:它擅长“学新东西但别忘旧东西”,不擅长做特别激进的行为重塑。
- 成本更高:需要 on-policy generation,论文报告约 2.5x FLOPs 和约 4x wall-clock。
- 会学到 teacher 的表面伪影:比如 “Based on the text...” 这类前缀,需要额外 heuristic 处理。
11. 如果只记住一句话
continual learning 的关键,不只是“别更新太猛”,而是“在模型自己会访问到的状态分布上学习”。 SDFT 的价值就在于,它把 demonstration learning 从“离线模仿专家”推进到了“在线纠正自己”。
参考与出处
- Shenfeld et al., Self-Distillation Enables Continual Learning, arXiv:2601.19897, 2026.
- 文中关键实验和论点主要对应论文 Figure 1-6、Table 1-2、Table 5,以及 Section 3-5。