从轨迹到技能:模型自动生成 Agent Skills 全生命周期的系统研究
精读 arXiv 2605.23899,全面解析 Agent Skill 生命周期三阶段(经验生成、技能抽取、技能消费)中的关键发现与工程启示。
Paper Reading
一句话:第一个系统性研究"模型自己给自己提炼 Skill"全链路有效性的工作。
适合读者:对 LLM Agent 系统、Skill/Memory 机制、Agent 自我进化感兴趣的研究者和工程师。
论文:From Raw Experience to Skill Consumption: A Systematic Study of Model-Generated Agent Skills
作者:Zisu Huang, Jingwen Xu, Yifan Yang et al. (Fudan University & Microsoft Research & SJTU)
链接:arXiv:2605.23899 (May 2026)
阅读时长:约 20 分钟
难度:中等(需了解 LLM Agent 基本概念、Prompt Engineering)
TL;DR
- 这是第一篇系统性覆盖 Skill 全生命周期(经验生成 → 技能抽取 → 技能消费)的大规模实证研究。
- 横跨 5 个领域(ALFWorld / SpreadsheetBench / SWE-bench / SEAL / BFCL)、6 个 Target 模型、5 个 Extractor 模型,共计数百组实验。
- 提出两个新指标:Extraction Efficacy (EE)(抽取者能力)和 Target Evolvability (TE)(消费者进化力)。
- 核心发现:模型自动抽取的 Skill 在多数场景有效(正 Δ),但存在显著方差;决定 Skill 质量的不是格式/文笔,而是失败机制编码、可执行的操作级指令、高风险动作黑名单。
- 基于对比分析构建了 Meta-Skill Guided Extraction,用 3 维验证过的指导 rubric 平均提升 +1.55pp。
1. 这篇论文到底解决什么问题?
现代 LLM Agent 通过在推理时加载"Skill"(结构化的过程性知识片段)来复用历史经验,无需重新训练。 商业 Agent 平台(如 Codex、Cursor、各种 Agent Framework)都已将 Skill 作为标配组件。 但问题是:
- 手写 Skill 不 scale:Agent 能力和部署领域飞速扩展,人工维护跟不上。
- 模型自动生成的 Skill 到底有没有用? 现有工作各自为政,没有统一评估框架。
- 什么决定了 Skill 的有效性? 是抽取方法?是经验质量?还是消费模型能力?
已有 benchmark(SkillsBench、SWE-Skills-Bench、SkillCraft)只覆盖 lifecycle 的一个阶段。 本文第一次端到端、跨阶段、跨模型、跨领域地研究这个问题。
2. 方法总览:Skill 全生命周期 Pipeline
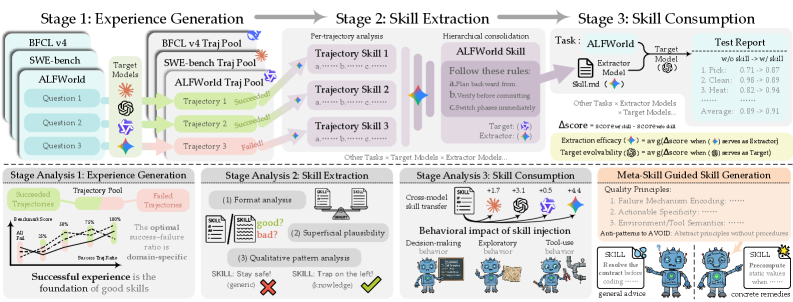
经验生成
Target 模型 M 在 train split 上执行任务,产生经验池 T = {(task, trajectory, outcome)},包含成功和失败轨迹。
技能抽取
Extractor 模型 E 对经验池做 per-trajectory 分析 + 层次化合并(hierarchical consolidation),输出结构化 Skill。
技能消费
同一个 Target M 带着抽取出的 Skill 在 test split 上评测,衡量 Δ = Perf(with skill) - Perf(baseline)。
设计关键决策
- Skill 来源于 Target 自己的经验:模拟真实部署场景(从自己的 log 中自我进化)。
- Extraction Framework 故意极简:不加领域 heuristic、不做 filter/optimization,让实验差异归因于 Extractor 能力本身。
- 固定 Target 变 Extractor(EE)/固定 Extractor 变 Target(TE):解耦两端贡献。
3. 核心模块拆解:Extraction Framework
3.1 Per-trajectory 分析(Map 阶段)
Extractor 独立处理每条轨迹 τi,产出一个 pattern set ui(每条最多 K=3 个 pattern)。 Pattern 包含 success patterns(成功策略)和 failure patterns(失败模式)。 这一步完全可并行化。
3.2 层次化合并(Reduce 阶段)
以 group size G=10 做 tree-structured reduction:每层将 G 个 pattern sets 合并为 1 个,去重、泛化、协调冲突, 直到归并为单一 consolidated pattern set。最终通过 tool-calling 操作将其转为结构化 Skill(name/description/body/references/scripts)。
3.3 Skill 表示与消费
Skill 遵循 Agent Skills 开放标准,字段包括 name、description、body(Markdown 过程性指令)、可选 references 和 scripts。 消费时:
- 单 Skill:直接 inline 到 system prompt。
- 多 Skill:通过 progressive disclosure(list_skills → view_skill → read_skill_file)按需加载。
4. 主实验结果:Skills 到底有没有用?
实验规模
5 Domains × 6 Targets × 5 Extractors = 150 组 (E, M, D) 实验。每组都有完整的经验生成 → 抽取 → 消费流程。
4.1 总体结论
Skill 总体有效
多数 (E, M, D) 组合产生正 Δ。SpreadsheetBench 和 BFCL 几乎全面正收益;SWE-bench 也普遍有效(30 组中 28 组 Δ > 0)。
方差巨大
同一领域,Δ 从 -5.72pp 到 +14.66pp 不等。Extractor-Target 匹配非常关键。
已强模型难受益
Gemini-3.1-Pro 在 ALFWorld 基线 87.56%,Skill 几乎无法再提升;而较弱模型提升更明显。
负迁移存在
Qwen3.5-9B 和 Gemini-3.1-FL 在 ALFWorld 出现全面负 Δ,说明 Skill 消费需要一定能力门槛。
4.2 EE vs TE 分析
| 指标 | 含义 | Top Performer |
|---|---|---|
| EE (Extraction Efficacy) | 固定 Extractor,对所有 Target 平均 Δ | GPT-5.4-mini 和 Gemini-3.1-FL 表现最好 |
| TE (Target Evolvability) | 固定 Target,所有 Extractor 给它的平均 Δ | GPT-5.4 和 Gemini-3.1-FL 受益最大 |
有趣发现:最好的 Extractor 不一定是最强的模型。GPT-5.4-mini 在多个领域的 EE 超过 GPT-5.4, 说明抽取能力和任务解题能力不完全正相关。
5. 深度分析:三个阶段各有什么发现?
5.1 经验生成:成功轨迹 vs 失败轨迹?
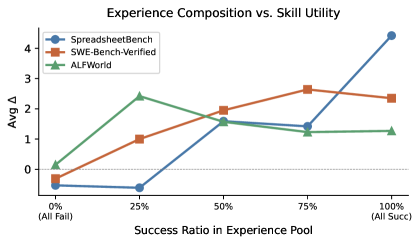
- 混合经验池(包含成功+失败)通常最好:失败轨迹提供了"不该做什么"的关键信号。
- 但在部分领域(如 SWE-bench),pure success 也足够好,因为成功轨迹本身已包含大量试错。
- 经验池大小有 diminishing returns:增加到一定量后 Skill 质量趋于饱和。
5.2 技能抽取:什么让 Skill 好用?
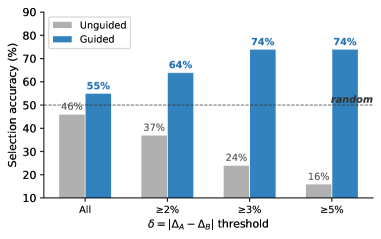
核心发现:格式不影响,内容才关键
将同一 Skill 改写为 ordered list / unordered list / checklist / prose 四种格式后评测: 格式无显著影响(所有 p > 0.34)。真正决定 Skill 有效性的是其内容中编码的知识类型。
通过对比分析 151 对高/低 Δ Skill,论文发现了三个经过效用验证的质量维度:
失败机制编码
好 Skill 能编码"为什么 Agent 会失败"(如公式注入假象、索引偏移),而非仅说"注意这里可能出错"。Better-rate: 65.5%
可执行的操作级指令
好 Skill 包含引用具体 tool/对象的 step-level 操作流程,而非抽象的过程性建议。Better-rate: 66.0%
高风险动作黑名单
好 Skill 明确禁止特定有害的动作模式(如"永远不要在 headless 环境中写 Excel 公式")。Better-rate: 64.6%
5.3 技能消费:不同模型如何响应 Skill?
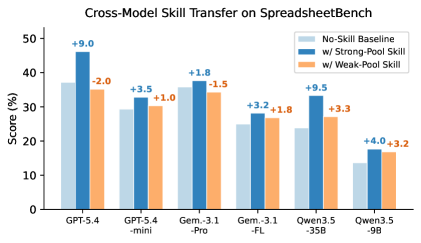
- 强模型:策略矫正为主。GPT-5.4 消费 Skill 后主要是"选择更可靠的策略"(如用 Python 算值而非写 formula),不是获得新能力。
- 弱模型:双刃剑。Qwen3.5-9B 消费 Skill 后倾向于采用更复杂的流程,增加了结构正确性但也增加了执行出错风险。
- 能力门槛:存在一个"消费能力门槛"——如果模型太弱,无法正确执行 Skill 中的指令,反而会导致负迁移。
6. From Diagnosis to Intervention:Meta-Skill Guided Extraction
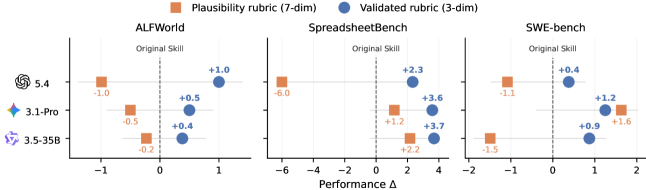
基于上述分析,论文提出了一个自然的 follow-up:能否把对"好 Skill"的理解反馈给抽取过程本身?
做法
- 从对比分析中提炼出 7 个候选质量维度。
- 通过下游效用验证筛选出 3 个有效维度(即上述三个)。
- 将这 3 维 rubric 作为 "Extraction Quality Guidance" 注入到抽取 prompt 中。
结果
| Guidance | 平均 Δ vs Original |
|---|---|
| Plausibility rubric (7-dim, 未验证) | -0.59 pp |
| Validated rubric (3-dim, 效用验证) | +1.55 pp |
关键教训
直接让 LLM"想象什么是好 Skill"(plausibility rubric)不仅无效,还会伤害效果。 只有经过下游效用验证的维度才能可靠地指导抽取。 这与 RLHF 中"好的 reward model 需要 ground truth signal"的思路一致。
7. 对比案例:好 Skill vs 差 Skill
SpreadsheetBench 案例
Gemini-3.1-FL 抽取
编码了三个领域特定失败机制:
(1) Formula Injection Fallacy—headless 环境不执行公式,必须预计算静态值;
(2) 逆序迭代避免 index-shifting;
(3) 动态寻址替代硬编码坐标。
每个机制都配有可执行的补救措施。
GPT-5.4 抽取
停留在过程级指导("先确认合约"、"最小化编辑"、"验证结果"), 合理但太抽象,无法阻止实际会触发的具体失败模式。
ALFWorld 案例
Gemini-3.1-Pro 抽取
提供了三个映射到 ALFWorld 动作词汇的可执行 pattern:
(1) Deep Inspection—必须显式 open 关闭容器;
(2) Active State Transformation pipeline;
(3) 先导航开门再放置的前置条件解决。
GPT-5.4 抽取
描述了相同的高层逻辑("找到瓶颈"、"管理前置条件"), 但抽象程度太高,无法直接对应 ALFWorld 的 action space。
8. 深度理解 Q&A
- Q1: 为什么 GPT-5.4-mini 作为 Extractor 经常比 GPT-5.4 好?
- 论文发现更强的模型做 Extractor 时倾向于生成更抽象、更"优雅"的 Skill——语言更好但可执行性更差。较小模型反而因为能力限制被迫停留在操作级细节,这恰好是高效 Skill 所需的。
- Q2: Skill 消费的"能力门槛"大致在哪?
- 从实验看,Qwen3.5-9B(~9B 参数)在多个领域出现负迁移,35B 基本能正向受益。但这不纯粹是参数量问题——Gemini-3.1-FL 虽然是大模型但在 ALFWorld 也出现负迁移,可能与该模型对 embodied task 的 instruction following 能力有关。
- Q3: 格式真的完全不 matter 吗?
- 在控制变量实验中(同一 Skill 内容,四种格式),Friedman test 显示格式效应的 σ-ratio 全部 < 1(低于 run-to-run 噪声),即格式效应小于随机评测噪声。相比之下,Extractor 的效应 σ-ratio 最高达 4.53。
- Q4: 经验池需要多大?
- 论文发现存在 diminishing returns——达到一定量后(具体取决于领域复杂度),增加经验不再显著提升 Skill 质量。这与直觉一致:Skill 编码的是领域级的 recurring patterns,而非 per-task solutions。
- Q5: 这个 Framework 如何推广到实际系统?
- 实际意义非常直接:(1) 部署后收集 Agent 交互 log;(2) 用 GPT-5.4-mini 等 Extractor 做 map-reduce 抽取;(3) 注入 system prompt 或通过 skill tool protocol 暴露;(4) 定期用下游指标验证 Skill 效用并迭代。论文的 meta-skill guidance 可作为抽取质量把关的轻量干预。
- Q6: 与 RL-based 方法(如 ProcMem、CoEvoSkills)的关系?
- 本文的 extraction framework 是 prompt-based distillation 的极简版。RL-based 方法(如 ProcMem 的非参数 PPO)理论上能进一步优化 Skill,但本文证明了即使是最简单的 map-reduce 抽取也能产生显著收益——RL 的额外复杂度是否值得需要在同一框架下对比。
- Q7: 负迁移的根因是什么?
- 行为分析显示主要有两类:(1) Skill 引导模型采用更复杂的流程但模型能力不足以执行(如 Qwen-9B);(2) Skill 编码了对当前 Target 不适用的策略(如为 Python-native 工作流设计的 Skill 被注入到偏好 formula-native 的模型)。
9. 工程/研究启发
Skill 作为 Agent 自进化原语
本文证明了 log → skill → self-improvement 闭环在实践中可行。对于 Agent 系统,应将 Skill 抽取作为标准 post-deployment 流程。
抽取器选型
不要默认用最强模型做抽取——中等模型(如 GPT-5.4-mini)可能更好。选型时应考虑 "operational specificity" 倾向。
Skill 质量把关
写 Skill 时检查三件事:(1) 编码了哪些具体失败模式?(2) 指令是否可执行到 tool-level?(3) 有没有明确的"不要做 X"?
消费端适配
强模型给 strategy correction 就够了;弱模型需要更 defensive 的 Skill(更短、更保守、避免引入复杂流程)。
参考与出处
- Huang, Z., Xu, J., Yang, Y. et al. "From Raw Experience to Skill Consumption: A Systematic Study of Model-Generated Agent Skills." arXiv:2605.23899, May 2026.
- Agent Skills Open Standard: github.com/agentskills/agentskills
- 本文覆盖的 Benchmark: ALFWorld, SpreadsheetBench, SWE-bench-Verified, SEAL-0, BFCL-v4