SkillOpt 论文精读:把 Agent Skill 当成可训练参数
解读 SkillOpt 如何用 rollout、反思、文本学习率和验证门,把冻结 Agent 的技能文档训练成可迁移的程序性知识。
Paper Reading · arXiv:2605.23904v2 · 2026-05-25
SkillOpt 的关键主张:不要只“写” skill,而要像训练模型参数一样“训练” skill。
论文 SkillOpt: Executive Strategy for Self-Evolving Agent Skills 来自 Microsoft、上海交通大学、同济大学和复旦大学。它把自然语言 skill 文档定义为冻结 Agent 的外部可训练状态:目标模型只负责执行,另一个更强的优化器模型负责从轨迹中提出受限编辑;只有在 held-out selection split 上变好,编辑才被接受。
适合读者:熟悉 LLM agent、prompt/skill 工程、工具调用评测或无权重更新适配的读者。本文会把论文中的“深度学习类比”拆成可操作的训练循环。
训练对象
不是模型权重,而是一份 best_skill.md。它承载流程、工具策略、格式约束和失败模式,部署时不额外调用优化器模型。
优化算法
rollout batch 提供证据,minibatch reflection 产生 add/delete/replace,文本学习率限制每步编辑数,验证门决定是否接受。
经验结论
论文报告 SkillOpt 在 52/52 个 model-benchmark-harness 单元上最优或并列最优;GPT-5.5 direct chat 平均从 58.8 提升到 82.3。
我的判断
这篇工作的价值不只是“自动改 prompt”,而是把 skill 演化做成了有 batch、learning rate、validation 和 negative feedback 的可审计训练过程。
TL;DR
- 问题:Agent skill 通常靠人工、一次性生成或松散自我修订,缺少稳定、可复现、可验证的优化过程。
- 方法:SkillOpt 用冻结目标模型执行任务,用 frontier optimizer model 从成功/失败轨迹中提出受限文本编辑,再用 held-out selection split 过滤。
- 核心机制:文本学习率
L_t控制每步最多接受多少条编辑;rejected-edit buffer 记住失败更新;slow/meta update 跨 epoch 汇总长期方向。 - 证据:论文覆盖 6 个 benchmark、7 个目标模型、3 种执行模式,并展示跨模型、跨 harness、跨数学 benchmark 的正迁移。
- 边界:它仍依赖可打分任务、训练/选择 split 和强优化器;开放式任务的 gate、数据泄漏控制和真实生产长周期漂移仍需更多验证。
1. 这篇论文到底解决什么问题?
在 Agent 场景里,“适配”不只意味着模型知道更多事实,也意味着它知道该怎么做事:先查哪个证据、什么时候调用工具、如何验证文件输出、答案要保留什么单位、失败时该重试什么策略。论文把这种程序性知识称为 agent skill:一份可移植的自然语言 artifact,包含流程、领域启发、工具策略、输出约束和失败模式(p.2, S002)。
问题在于,现有 skill 多半像 prompt engineering:人工写、LLM 一次性生成,或在失败后做松散自我修订。它们可能有用,但不像一个训练算法:没有 batch 噪声控制,没有 step size,没有 validation gate,也没有“哪些更新失败了”的负反馈记忆。因此,作者提出一个更强的设定:如果 skill 是 Agent 的程序性适配层,那么 skill 文档本身就应该被训练(p.1-p.2, S001-S003)。
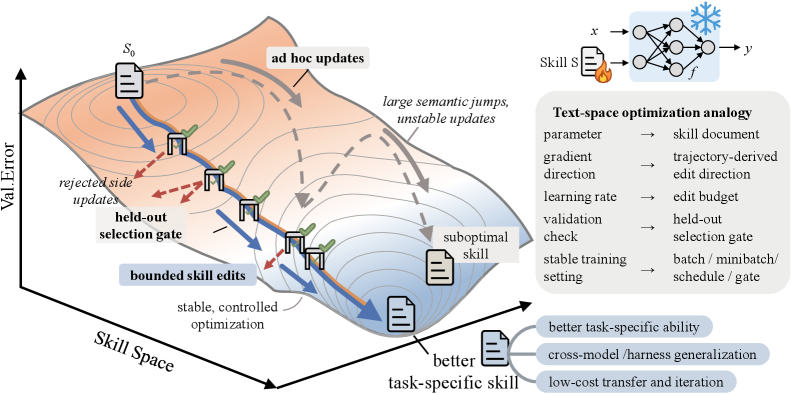
2. 方法总览:把文本编辑变成训练循环
SkillOpt 的对象很明确:给定训练集 D_tr、选择集 D_sel、测试集 D_test,它只用 D_tr 产生候选 skill,用 D_sel 接受或拒绝候选,最后只在 D_test 报告性能(p.4, S004)。这使它更接近机器学习中的训练/验证/测试分工,而不是在测试集上反复调 prompt。
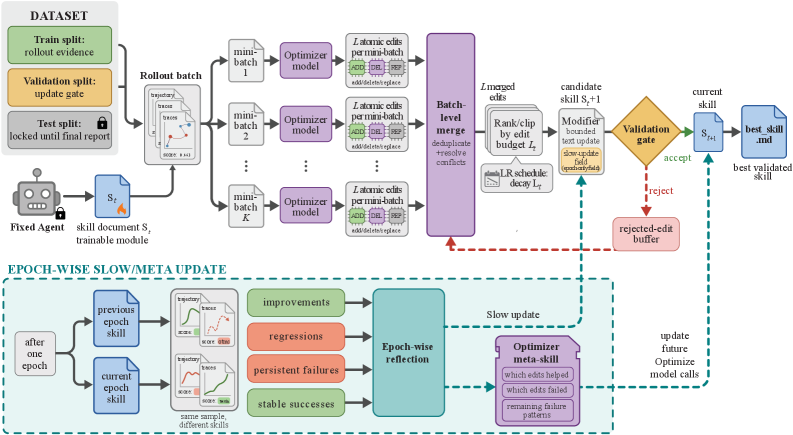
把 SkillOpt 翻译成优化器术语
- 参数:skill document,而不是 neural weights。
- batch:目标模型带当前 skill 跑出的 scored trajectories。
- 梯度方向:优化器模型从失败/成功 minibatch 中总结出的文本编辑方向。
- learning rate:每步最多应用的编辑数
L_t,而不是连续数值步长。 - validation:候选 skill 必须在 held-out selection split 上严格提升;tie 被拒绝。
- momentum / long horizon memory:epoch-wise slow/meta update 记录长期有效或失败的编辑模式。
3. 核心模块拆解
3.1 Forward pass:rollout batch 是证据单元
每一步,冻结目标模型 M 会带着当前 skill 在训练任务上执行,harness 记录消息、工具调用、观察、命令输出、最终答案、verifier feedback,以及特定 benchmark 的上下文,例如表格预览或文档引用。论文强调 batch 是 evidence unit:太小会变成 anecdotal fix,太大则更新慢(p.4, S005)。
3.2 Backward pass:minibatch reflection 不是单条失败复盘
优化器模型会把轨迹分成失败 minibatch 和成功 minibatch。失败样本用于提出缺失或纠错规则,例如“总是查错来源”“答案格式不符合 scorer”;成功样本用于保留已经有效的行为,避免后续编辑把好规则删掉。随后,局部建议会先在失败/成功侧分别合并,再以 failure correction 为优先级合成最终候选(p.5, S006)。
3.3 文本学习率:为什么不能让 LLM 随便重写 skill?
SkillOpt 最有意思的设计是把 learning rate 变成编辑预算 L_t:每个 step 最多应用多少条 add/delete/replace。作者的理由很实用:无限制重写会删除有用规则、引入互斥指令,或过拟合某个局部失败;受限编辑则让相邻 skill 版本足够接近,使后续的 rejected edits 和 accepted edits 还能构成有意义的优化历史(p.5, S007)。
SkillOpt step (简化伪代码)
current_skill = s_t
trajectories = rollout(target_model, current_skill, train_batch)
edit_pool = reflect(optimizer_model, successes, failures, rejected_buffer)
ranked_edits = merge_and_rank(edit_pool)
candidate = apply_top_L_edits(current_skill, ranked_edits, L_t)
if score(candidate, D_sel) > score(current_skill, D_sel):
s_{t+1} = candidate
update(best_skill if candidate is best)
else:
rejected_buffer.add(candidate_edits, score_drop)
3.4 Validation gate:把“自我反思”变成 propose-and-test
候选 skill 只有在同一个冻结目标模型、同一个 harness、同一个 selection split 上严格超过当前 selection score,才会被接受;否则拒绝。这个 gate 的意义在于:LLM 产生的文本诊断听起来合理,并不代表它真的改善目标模型行为。SkillOpt 让文本反思必须通过外部 scorer 的检验(p.5, S008)。
3.5 Rejected buffer 与 slow/meta update:稳定训练的两个记忆
被拒绝的编辑不会直接丢弃,而是进入 epoch-local rejected-edit buffer,让后续反思知道哪些方向已经试过且伤害了 selection score。跨 epoch 时,SkillOpt 还会比较前一 epoch skill 和当前 skill 在相同训练项上的表现,把 improvements、regressions、persistent failures、stable successes 写入受保护的 slow-update field;optimizer-side meta skill 会进入后续教师反思上下文,但不随 best_skill.md 部署(p.5-p.6, S008-S009)。
4. 实验:强结果来自哪里?
实验覆盖 SearchQA、SpreadsheetBench、OfficeQA、DocVQA、LiveMathematicianBench、ALFWorld 六类任务,目标模型包括 GPT 系列和 Qwen 系列,并测试 direct chat、Codex harness、Claude Code harness 三种执行模式(p.6-p.7, S010)。对比方法包括 no skill、human skill、one-shot LLM skill、Trace2Skill、TextGrad、GEPA,以及 harness 侧的 EvoSkill。
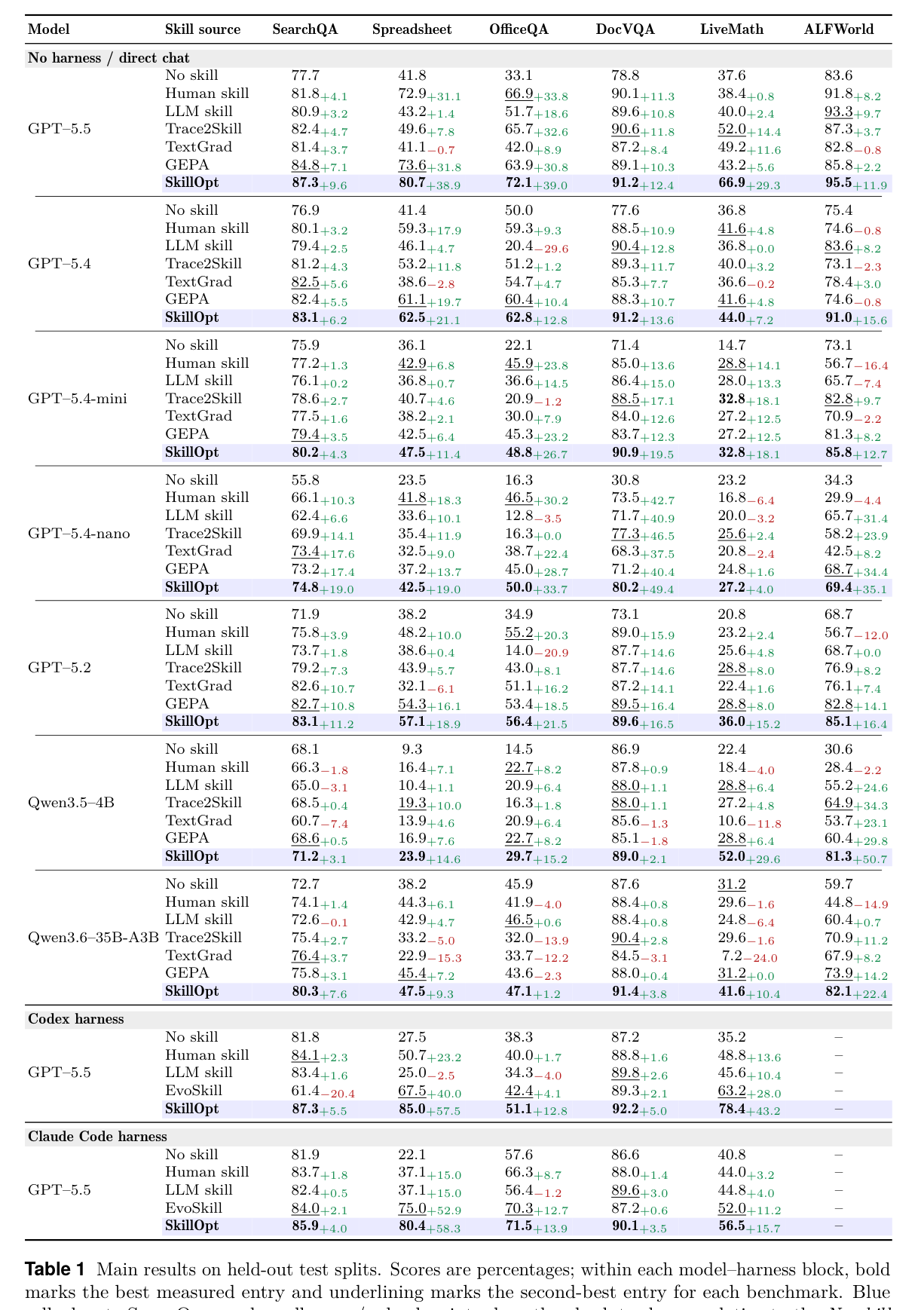
最值得注意的不是 SearchQA 这种接近 ceiling 的任务,而是程序性强、格式要求强的任务:GPT-5.5 direct chat 上 SpreadsheetBench 从 41.8 到 80.7,OfficeQA 从 33.1 到 72.1,LiveMath 从 37.6 到 66.9。我的理解是:这些任务并不只缺“知识”,而是缺稳定流程;skill 文档恰好可以外置这些流程。
5. 消融:哪些控制真正重要?
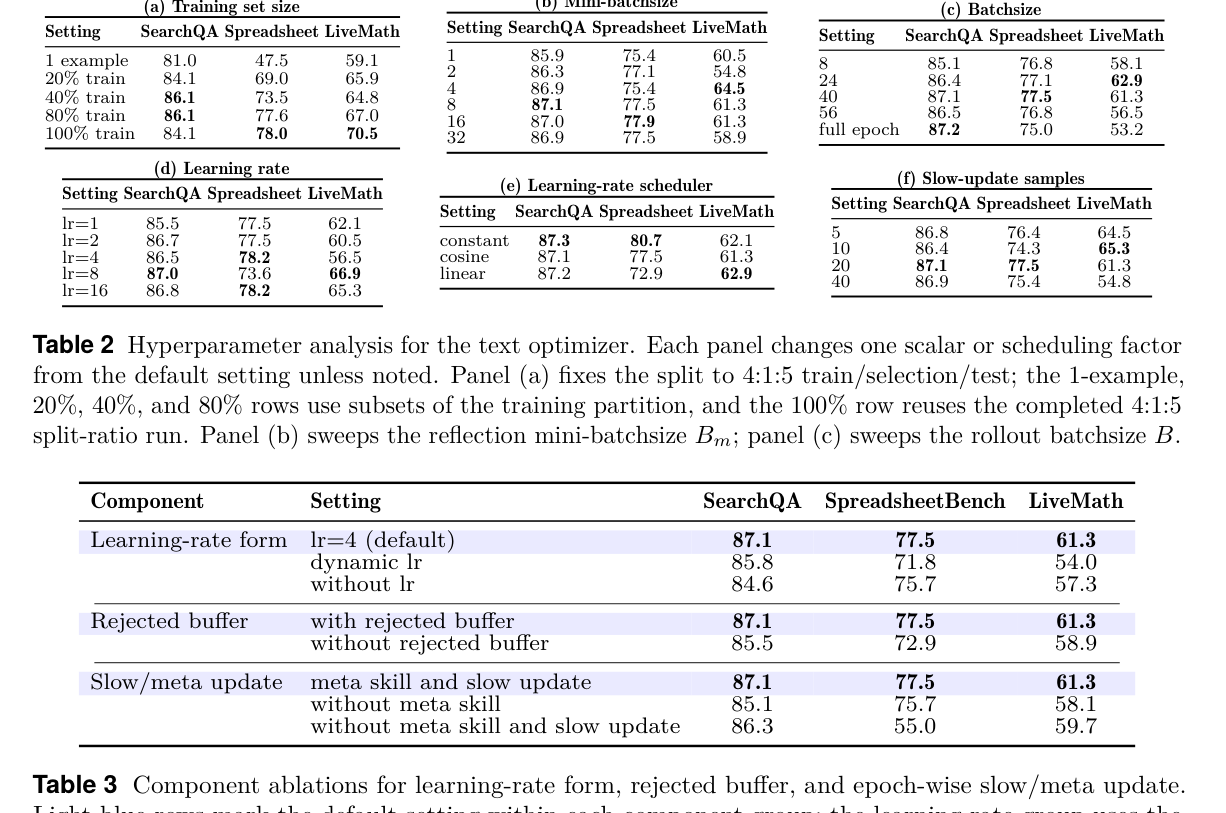
论文的 ablation 支撑了“受控优化”而不是“更长 prompt”这个解释。训练证据越多,SpreadsheetBench 和 LiveMath 越受益;reflection minibatch size 和 rollout batch size 在较宽范围内并不脆弱;learning-rate schedule 的具体形式不是唯一关键,关键是不要无界重写(p.11, S013)。
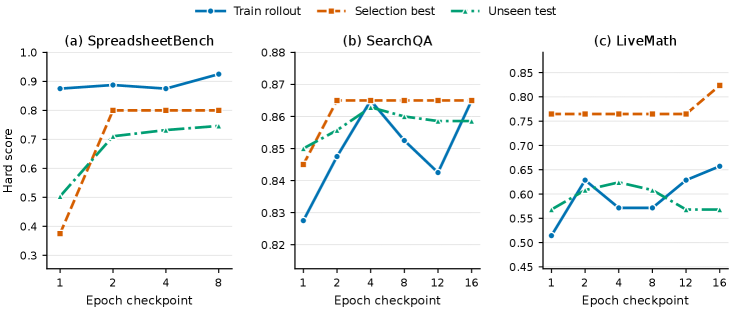
6. 迁移:skill 是 artifact 还是 benchmark prompt?
如果 SkillOpt 只是把某个 benchmark 的格式提示背下来,那么它跨模型、跨 harness 应该很脆弱。论文做了三类迁移:GPT-5.4 上训练的 skill 迁移到 GPT-5.4-mini/nano;Codex 与 Claude Code 之间互迁;OlympiadBench skill 迁移到 Omni-MATH。所有报告的迁移行都是正增益(p.13, S014)。
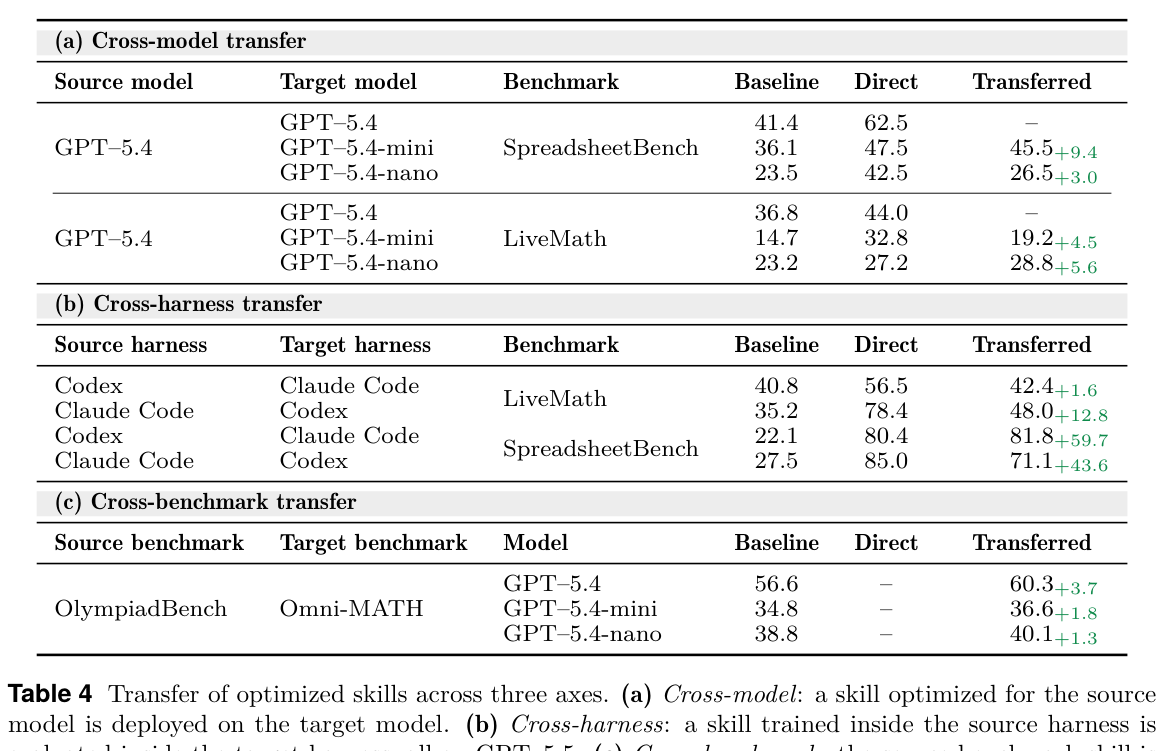
我的解读是:跨 harness 迁移尤其说明 skill 学到的不是“某个 CLI 命令怎么敲”,而是更高层的 workbook 处理程序,例如先检查结构、理解公式依赖、写入静态值、避免依赖 Excel 自动重算。这类流程在不同 agent harness 中都可能有用。
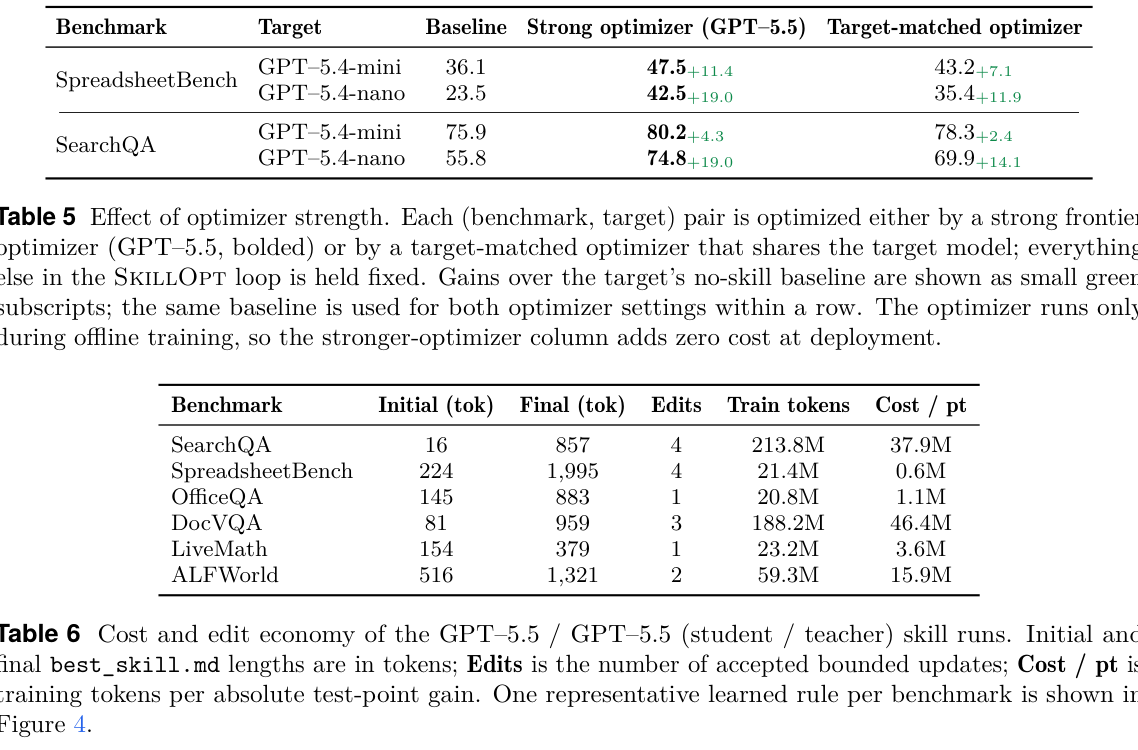
7. 成本与产物形态:小 skill,大训练
SkillOpt 的部署产物很小:论文报告 GPT-5.5/GPT-5.5 runs 中,最终 best_skill.md 大约 379 到 1,995 tokens,接受编辑数 1 到 4 次不等;优化器模型只在离线训练时使用,部署时没有额外模型调用(p.14, S015)。这使它区别于每次推理都要反思/自改/多代理投票的方法。
8. 局限与我会追问的问题
没有可靠 scorer 的开放任务怎么办?
SkillOpt 依赖 selection gate。对写作、设计、长期项目管理这类难以自动打分任务,可能需要 preference model、人类审核或多指标 gate;否则“严格提升”无从定义。
强优化器是否造成隐性蒸馏?
论文用 target-matched optimizer 做了对照,说明弱优化器也有收益,但强 frontier optimizer 更好。实际部署时,这像是把强模型的程序性策略离线蒸馏进文本 artifact。
selection split 会不会被过拟合?
严格 held-out gate 比无条件 self-edit 更可靠,但如果 step 很多、selection 很小,仍可能 selection overfitting。论文的 checkpoint/test 曲线给了支持,但生产系统还要监控长期漂移。
skill 文档如何组合?
本文训练单个 domain skill。真实 Agent 往往同时加载多个 skill,可能出现冲突、优先级、检索和上下文预算问题,这是下一步更接近系统工程的挑战。
9. 工程启发:如何把它用到自己的 Agent?
- 先定义可评分任务集:没有 scorer,SkillOpt 的 gate 就失效。即便是人工评分,也要区分 train/selection/test。
- 记录完整轨迹而非只看最终答案:工具调用、文件差异、stderr、验证器反馈才是 skill edit 的证据。
- 编辑要小而可审计:用 add/delete/replace patch,保留 edit_apply_report,避免“整份 skill 重写后没人知道变了什么”。
- 保留失败更新:prompt/skill 优化常犯的错是只记录成功经验;被拒绝的编辑同样是负样本。
- 把训练时记忆和部署时 skill 分离:meta skill 可以很长、很脏、很过程化;部署的 best_skill 应该短、稳定、可迁移。
一句话总结
SkillOpt 的贡献不是发明“让 LLM 改 prompt”,而是把 skill 改写放进一个更像优化器的框架:有 batch、有 step size、有 validation、有 rejected updates、有 slow memory。它给 Agent 工程一个很实用的方向:当你不能或不想改模型权重时,可以把可训练对象降维成一份可审计、可迁移、低部署成本的程序性 skill 文档。
参考与出处
- Yifan Yang et al. SkillOpt: Executive Strategy for Self-Evolving Agent Skills. arXiv:2605.23904v2, 2026-05-25.
- 论文链接:arXiv:2605.23904;代码入口:https://aka.ms/SkillOpt。
- 本文使用的页码与 source IDs 来自本仓库保存的
/assets/papers/skillopt-2605-23904/source_map.json。