SPD 论文精读:不用外部信号,如何把模型自己的能力“投影”出来?
解读 Self-Policy Distillation 如何用正确性 token 的梯度抽取能力子空间,再用 KV 投影生成更可蒸馏的数据。
Paper Reading · arXiv:2605.22675 · 2026
Self-Policy Distillation 的核心想法:不筛答案、不找奖励模型,而是先改变“自己生成数据时的内部表示”。
论文 Self-Policy Distillation via Capability-Selective Subspace Projection 来自 University of Cambridge、HKUST 和 University of Chicago。它针对自蒸馏中的一个微妙问题:模型自己生成的数据里,能力信号、格式习惯、解释风格、模型固有错误是混在一起的;直接训练会把这些一起学回去。
适合读者:熟悉 self-training / self-distillation、LoRA 微调、Transformer KV cache 或表示空间干预的读者。本文会重点解释“correctness-defining token → 梯度 → SVD → KV projection hook → 自生成语料 → LoRA 吸收”这条链路。
问题
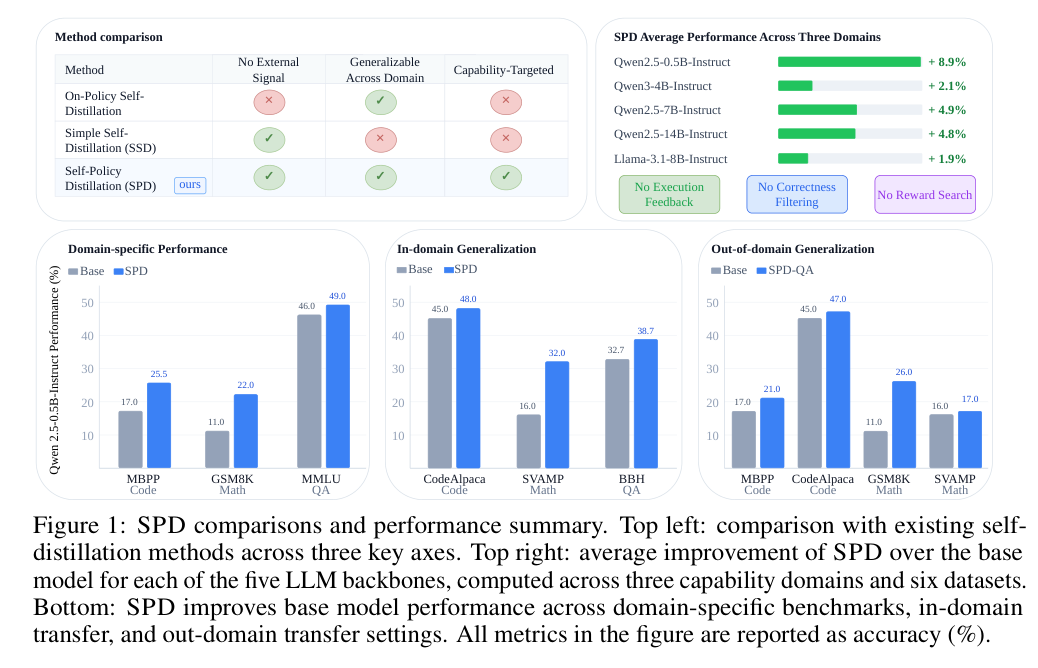
现有自蒸馏要么依赖 correctness filtering、execution feedback、reward search 等外部信号,要么直接吃 raw self-generated outputs,容易把错误和风格噪声一并强化。
方法
SPD 从少量 calibration examples 的“正确性 token”梯度中抽取低秩 K/V 能力子空间,生成时把 KV 激活投影进去,再用生成语料做普通 next-token LoRA 微调。
证据
论文在代码、数学、选择题 QA 三类能力上测试多个 Qwen/Llama backbone,报告最高比无外部信号 SOTA 自蒸馏方法提升 13%,比预训练 baseline 提升 16%。
我的判断
SPD 的价值不是“又一种数据过滤器”,而是把过滤位置前移到生成过程内部:先诱导一个 capability-selected self-policy,再把这个 policy 蒸馏回原模型。
TL;DR
- 核心矛盾:自蒸馏想利用模型自己的 on-policy 数据,但 raw outputs 同时包含能力、风格、格式 artifact 和错误,训练信号不纯。
- 关键设计:只在决定任务成败的 token 上算 loss,例如 GSM8K 的最终数字、MMLU 的答案字母、MBPP 的 assertion-relevant span。
- 内部选择:对这些 loss 关于 K/V activation 的梯度做 SVD,保留 top-r right singular vectors,得到能力相关的低秩投影矩阵。
- 生成阶段:不改参数,只在 decoding 时用 hook 把 K/V 激活投影到能力子空间,让生成数据更聚焦目标能力。
- 训练阶段:移除 hook,用 hooked model 生成的 prompt-completion pairs 做标准 next-token LoRA 微调。
1. 这篇论文到底解决什么问题?
自蒸馏的基本动机很直接:让模型在自己的分布上生成数据,再把这些数据训练回模型,减少 off-policy teacher data 带来的 train-inference mismatch。但论文指出,直接使用 self-generated outputs 有一个更深的问题:输出并不是“目标能力”的纯样本,而是把能力、解释风格、格式模板、数据集 continuation noise、模型特定错误混在一起(p.1-p.2, S001-S002)。
传统解决方式是外部筛选:执行代码测试、用 verifier 打分、reward-guided search、多样本一致性投票等。这些方法有效,但需要任务基础设施,也不一定适用于 frontier model 或缺少自动验证器的任务。SSD 这类方法则更“干净”:不依赖 verifier / reward / RL,直接用内部规则处理 raw outputs;但论文认为它仍偏向特定领域,且没有真正解决“哪些 token/表示才代表目标能力”的问题(p.1-p.3, S001)。
一句话区分 SPD 和普通 self-distillation
普通 self-distillation 是从 f_old 采样,再训练 f_new 模仿这些样本;SPD 先用内部投影诱导出 f_old^hook,从这个 capability-selected self-policy 采样,再让原模型吸收它的行为(p.5, S003)。
2. 方法总览:两阶段,但只在生成时“动手术”
SPD 分成两个阶段。第一阶段从少量带答案 calibration set 中抽取能力子空间;第二阶段在 self-generation 时把 K/V 激活投影到这个子空间,得到更聚焦的训练语料;最后移除 hook,用普通 LoRA next-token loss 微调模型(p.4-p.6, S002-S005)。
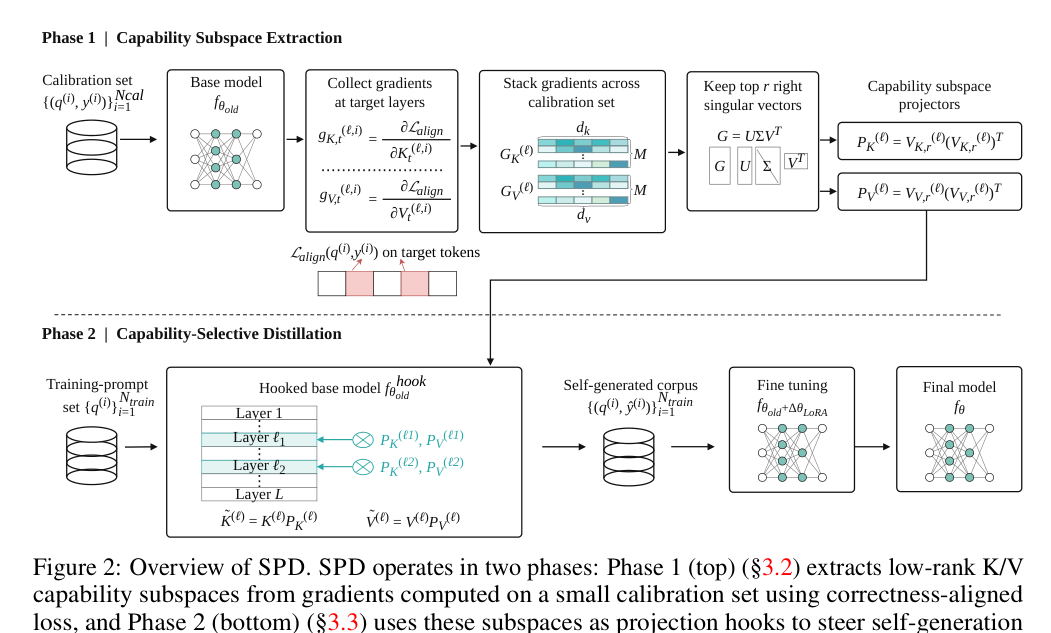
P_K 和 P_V。下半部分是 capability-selective distillation:hooked base model 生成语料,随后原模型通过 LoRA 吸收这些生成结果(p.4, F002)。不是参数编辑
projection hook 只在生成 self-training corpus 时存在;fine-tuning 和最终 evaluation 都移除 hook。它更像“生成数据的内部采样策略”。
不是外部 teacher
hooked policy 来自模型自己的梯度和激活空间,不提供外部 token-level label,也不需要 reward / verifier。
3. 核心模块拆解
3.1 Correctness-defining spans:先决定“哪些 token 真正算能力”
SPD 不在整段输出上计算 loss,而只选与任务成败直接相关的 target positions。论文称它们为 correctness-defining spans:代码任务用 assertion-relevant spans,数学任务用最终数字答案,选择题 QA 用 Answer: 后面的选项字母(p.5, p.15, S004, T006)。

形式上,给定 tokenized sequence z = T(q, y) 和正确性位置集合 S,aligned loss 是:
L_align(q, y) = - 1 / |S| * sum_{t in S} log p_theta_old(z_t | z_<t)
这个设计的直觉是:如果你想提升数学最终答案,不应该让“Therefore”“Let us solve”这类风格 token 主导梯度;如果你想提升选择题准确率,就应该让答案字母位置对梯度方向有最大话语权(p.5, E001)。
3.2 从梯度到低秩子空间:为什么是 K/V activation?
对每个 calibration example,SPD 对冻结模型做一次 forward-backward,收集 aligned loss 对目标层 key/value activation 的 token-level gradients。然后把这些梯度跨样本堆叠为矩阵 G_K^(l) 和 G_V^(l),对每个目标层做 SVD,保留 top-r right singular vectors,构造投影矩阵:
G_K^(l) = U_K^(l) Sigma_K^(l) (V_K^(l))^T
P_K^(l) = V_K,r^(l) (V_K,r^(l))^T
P_V^(l) = V_V,r^(l) (V_V,r^(l))^T
右奇异向量对应 K/V feature dimension 中最能解释 correctness-aligned 梯度变化的方向。把它们看作“正确性相关变化的主轴”即可:保留这些方向,压低低能量方向,有助于减少格式、风格、解释冗余等噪声对 self-generation 的影响(p.6, E002)。
3.3 Projection hook:在 decoding 时过滤 KV,不改权重
生成训练语料时,SPD 在目标层注册 hook,把当前 K/V activation 投影到前面得到的低秩子空间:
K_tilde^(l) = K^(l) P_K^(l)
V_tilde^(l) = V^(l) P_V^(l)
后续 attention 使用投影后的 K_tilde 和 V_tilde。重要的是:这一步不更新模型参数,只改变生成时的中间表示;生成完 prompt-completion pairs 后,hook 全部移除,原模型用这些 pairs 做 LoRA 微调(p.6, S005)。

4. 实验:SPD 到底强在哪里?
论文覆盖三类能力:代码生成(MBPP、CodeAlpaca-20k)、数学推理(GSM8K、SVAMP)、多选 QA(MMLU、BBH)。对于每个能力域,一个数据集作为 source benchmark,另一个作为 in-domain generalization;此外还做 QA-calibrated 子空间向 Math/Code 的 out-of-domain generalization(p.7, T001-T002)。
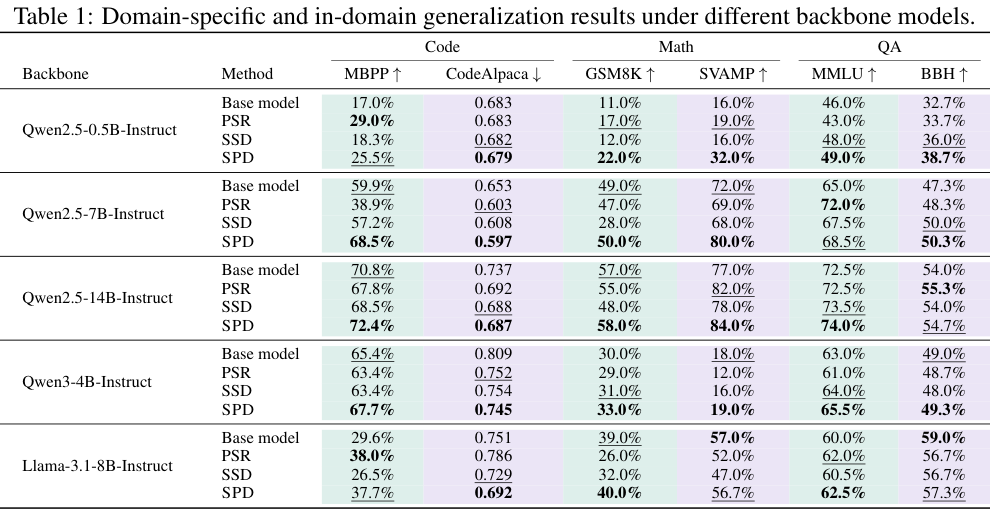
我认为最值得关注的是小模型上的数学提升:Qwen2.5-0.5B-Instruct 的 GSM8K/SVAMP 提升很大,说明 SPD 不只是让输出更短或格式更干净,而是在某些设置下改变了后续可学习的推理 supervision 分布。不过也要注意,Llama-3.1-8B-Instruct 上部分数学指标并非全面提升,例如 SVAMP 从 57.0 变为 56.7;这提醒我们 SPD 不是无条件单调增益,而是依赖子空间估计、backbone 和任务形态。
5. 跨域泛化:QA 子空间为什么能帮助 Math / Code?
论文做了一个很有意思的测试:只用 QA domain 抽取 subspace,然后把 SPD-QA 用到数学和代码上。结果中,Qwen2.5-0.5B-Instruct 的 MMLU/BBH 提升符合预期,同时 GSM8K 从 11.0% 到 26.0%,MBPP 从 17.0% 到 21.0%(p.8, T002)。
这里我的解读会更谨慎一点:QA 的 correctness span 是答案字母,看起来非常窄;如果它能帮到数学和代码,可能说明梯度方向捕捉到了“收敛到可评分答案”的表示模式,而不仅是特定领域知识。但论文目前只展示了有限任务和模型,仍需要更大规模的跨域矩阵来确认这是否是稳定规律。
6. 生成数据质量:SPD 改的是“采样出来的老师”
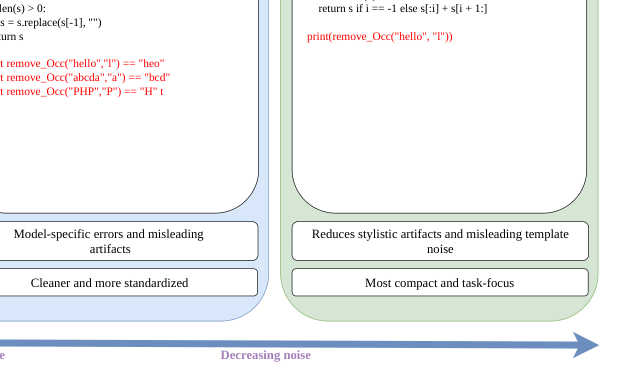
SPD 的中间目标不是直接在 benchmark 上答题,而是生成更适合后续训练的数据。论文的 qualitative example 显示,base model 输出容易混入解释、print、误导性说明;SSD 截断后更像模板,但仍可能保留错误程序逻辑;SPD 生成更短、更聚焦核心实现(p.8-p.9, F001)。

定量上,表 3 比较 fine-tuning 之前的 generated data quality;表 4 比较用不同 self-generated data 微调后的效果;表 5 证明 correctness-aligned loss 明显优于 full-sequence loss。尤其是 loss ablation:full-sequence loss 下 MBPP 只有 11.9%,而 correctness-aligned loss 为 25.5%;GSM8K 从 13.0% 到 22.0%;SVAMP 从 24.0% 到 32.0%(p.9, T003-T005)。

7. 数据效率与鲁棒性:50 个 calibration examples 够吗?
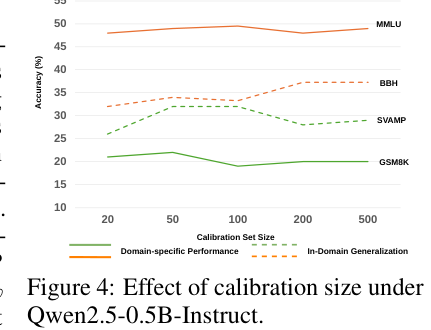
默认设置中,每个 domain 的 calibration size 是 50,target layers 是中间层和最后层,projection 同时作用于 K 和 V,LoRA rank 为 8(p.16, T007)。论文的 calibration size 分析显示,20 到 500 个 calibration examples 范围内,GSM8K、SVAMP、MMLU、BBH 的表现总体较稳定;作者据此认为少量 labeled examples 足以估计有用的 capability subspace(p.10, F002)。
8. 深度理解 Q&A
SPD 真的完全不需要标签吗?
不完全。它不需要外部 verifier/reward/teacher 来筛 self-generated outputs,但第一阶段需要少量 calibration examples 和 correctness-defining spans。因此更准确的说法是:生成语料和蒸馏目标不依赖外部筛选信号。
为什么不直接训练 correctness spans?
SPD 不是用 calibration set 本身做主要 SFT,而是用它估计“生成时应该保留哪些表示方向”。训练数据仍来自模型自己的 hooked generation,因此保留 on-policy self-distillation 的分布优势。
投影会不会损坏模型能力?
会有风险,所以 hook 只用于生成训练语料,而不是最终推理。即便生成阶段被压缩到低秩子空间,最终模型还是通过 LoRA 吸收这些样本,evaluation 时不再使用 hook。
这和 activation steering 有什么关系?
二者都在表示层干预模型行为。但 SPD 的 steering vector/subspace 不是人工指定属性或 contrastive direction,而是从 correctness-aligned gradients 中自动抽取,并服务于自蒸馏数据生成。
最大弱点是什么?
correctness-defining spans 的定义很关键。对于开放式写作、多轮 agent 或没有明确最终答案的任务,很难定义哪些 token 直接决定成功,SPD 的第一阶段会变得不自然。
为什么说它是 self-policy distillation?
因为蒸馏对象不是原始 f_old 的输出,而是内部变换后的 f_old^hook。这个 hooked policy 仍来自学生自身,但已经被 capability subspace 选择过。
9. 工程/研究启发
- 把数据过滤前移到生成过程:如果直接筛输出成本高,可以考虑在生成时控制表示,让候选数据天然更聚焦。
- 用小标注集定义能力,而不是训练全部能力:calibration set 的角色是“定位子空间”,不是承担主要监督学习。
- 正确性 token 选择决定上限:代码、数学、选择题都有明确 scorer;开放式 agent 任务需要新的 span 定义或轨迹级 proxy。
- 关注负迁移和 backbone 差异:表 1 中并非所有指标都提升,部署时应保留 held-out validation,而不是默认 SPD 一定优于 baseline。
- 可以和外部验证结合:SPD 的卖点是无 external curation,但在工程系统里,它也可以先生成更好的候选,再接执行器/verifier 做二次筛选。
一句话总结
SPD 的关键贡献是把自蒸馏中的“数据选择”从输出层筛选,改造成表示层的 self-policy 诱导:用正确性 token 的梯度找到能力子空间,用 KV projection hook 生成更聚焦的自训练语料,再把这个内部选择过的行为蒸馏回原模型。它很适合那些有少量标准答案、但不想构建 verifier/reward/search pipeline 的场景。
参考与出处
- Guangya Hao, Yitong Shang, Yunbo Long, Zhuokai Zhao, Hanxue Liang. Self-Policy Distillation via Capability-Selective Subspace Projection. arXiv:2605.22675, 2026.
- 论文链接:arXiv:2605.22675;本文使用的 PDF 与 source map 已保存到
/assets/papers/spd-2605-22675/。 - 文中页码和 source IDs 来自本仓库生成的
public/assets/papers/spd-2605-22675/source_map.json。